Help Center
Dokumentation
1. Einführung
integraid ermöglicht dir die schnelle und unkomplizierte Anbindung sämtlicher APIs direkt in Salesforce und sorgt so für eine nahtlose Integration externer Systeme sowie eine effiziente Datenverwaltung.
Die folgende Dokumentation gibt dir detaillierte Informationen zur App und beschreibt alle Schritte, die bezüglich Installation und Konfiguration zum erfolgreichen Einsatz von Integraid notwendig sind.
Du hast Fragen oder benötigst Unterstützung bei der Einrichtung? Schreibe uns einfach eine Email an support@integraid.app und wir helfen dir umgehend weiter.
1.1. Funktionen
integraid bietet dir folgende Funktionalitäten direkt in deiner eigenen Salesforce-Umgebung:
- Unkomplizierte und schnelle Integration externer APIs direkt in Salesforce.
- Problemlose Kommunikation externer Systeme mit Salesforce, ohne zusätzliche Middleware oder komplexe Integrationslösungen.
- Zentrale und effiziente Verwaltung der Daten sorgt für einen konsistenten Datenfluss zwischen externen Systemen und Salesforce.
Sämtliche Funktionalitäten sind (je nach Präferenz) vollständig automatisierbar. Dabei greifen Integraid und Salesforce-native Automationsmöglichkeiten nahtlos ineinander.
Diese Auflistung dient der Übersicht. Im weiteren Verlauf werden wir diese Funktionen einzeln und detailliert beschrieben.
1.2. Voraussetzungen
integraid ist ausschließlich für den Einsatz in Salesforce ausgelegt. Dabei ist es kompatibel mit folgenden Salesforce Editionen: Platform, Enterprise, Unlimited.
Einschränkungen gibt es bei der Salesforce Professional Edition.
1.3. Die Oberfläche von integraid
Die Oberfläche zur Konfiguration und Nutzung von integraid setzt sich ausschließlich aus nativen Salesforce-Bestandteilen zusammen. Folgende Reiter findest du in der Applikation:
| Tab | Beschreibung |
|---|---|
| Home | Auf der Startseite findest du aktuelle Dashboards deiner durch integraid verknüpften APIs. |
| Configurations | Mit Hilfe eines bei der Konfiguration angelegten Datensatzes "Configuration" steuerst du die Grundeinstellungen und Regeln der Anwendung. |
| Providers | Hier erstellst und verwaltest du deine API - Schnittstellen. |
| Endpoints | Hier erstellst und verwaltest du die Endpunkte deiner Provider. |
| Mappings | Hier erstellst und verwaltest du deine Mappings. |
| Jobs | Hier siehst du eine Liste aller deiner erstellten Jobs. |
| Results | Liste der meisten in der Anwendung durchgeführten Aktionen mit dem jeweiligen Ergebnis und Informationen über ggf. aufgetretene Fehler. |
Dieser Überblick dient der besseren Verständlichkeit der nachfolgenden Dokumentation. Details zur Nutzung der einzelnen Reiter werden später ausführlich gegeben.
2. Installation und Setup
Zur Nutzung von integraid sind einige vorbereitende Schritte notwendig. Diese umfassen natürlich die Installation des Tools selbst, aber auch weiterführende konfigurative Maßnahmen, die wir in diesem Kapitel beschreiben.
Hinweis: Bei dem Erwerb von integraid bieten wir einen kostenlosen Einrichtungsservice an! Schreibe uns einfach eine Email an support@integraid.com.
2.1. Installation
Die Installation von integraid erfolgt via Salesforce AppExchange.
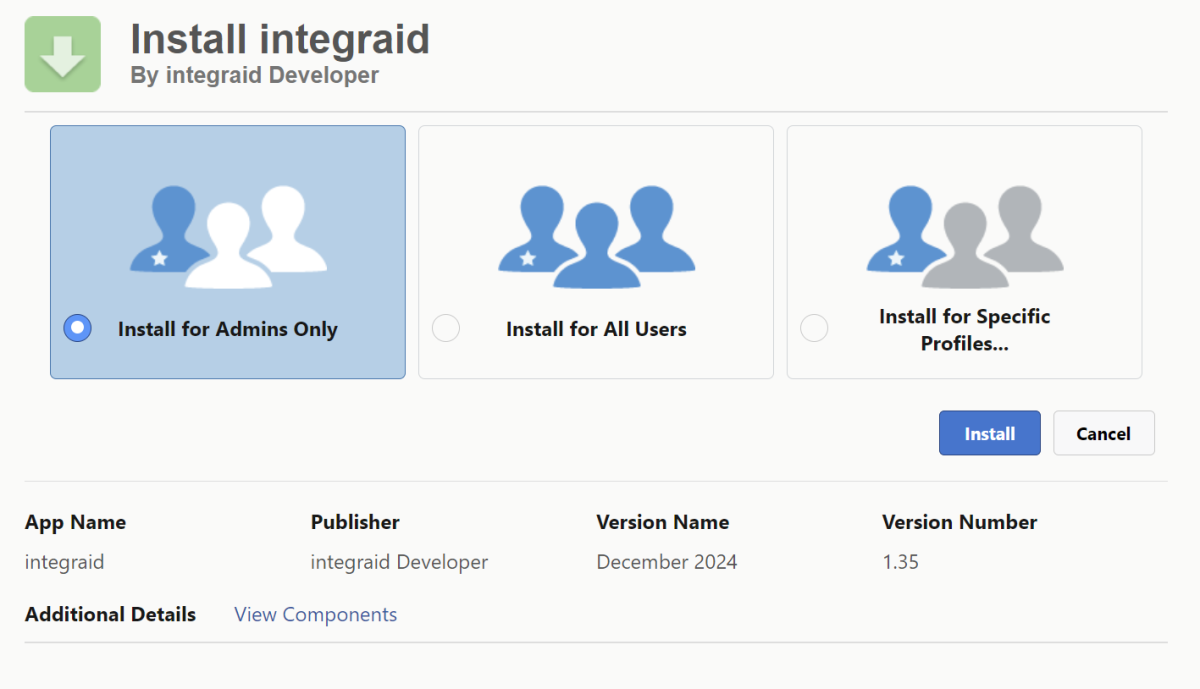
Klicke auf den Button "Get It Now", um den Installationsprozess zu starten.
Wenn du auf der Installationsseite bist, wähle „Nur für Administratoren“. Diese Auswahl ist erforderlich, da sonst auch nicht-autorisierte Nutzer Zugriff auf sensible Daten erhalten könnten.
 X
X
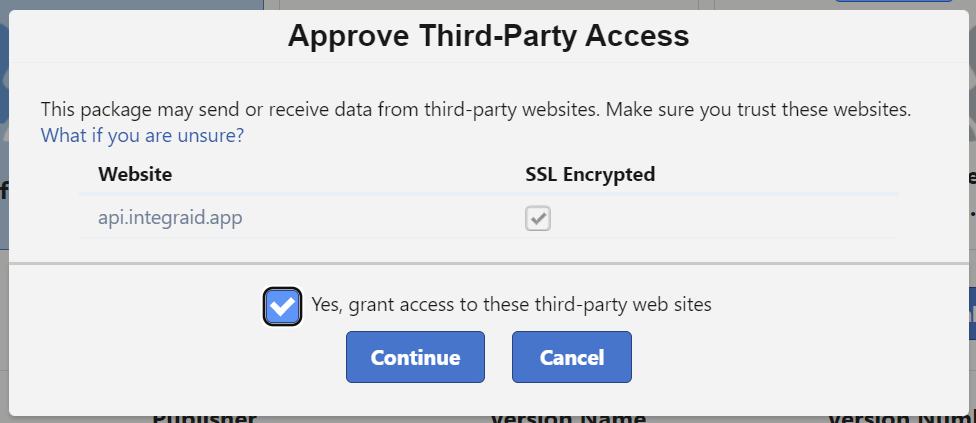
Klicke auf "Installieren" und bestätige die Meldung "Ja, den Zugriff auf diese Websites Dritter gewähren".
Hintergrund: Im Rahmen der Installation muss die Freigabe erteilt werden, verschiedene Schnittstellen anzusprechen. Neben der Schnittstelle muss auch die Kommunikation mit den Servern von integraid für den reibungslosen Betrieb des Tools hergestellt werden.
 X
X
 X
X
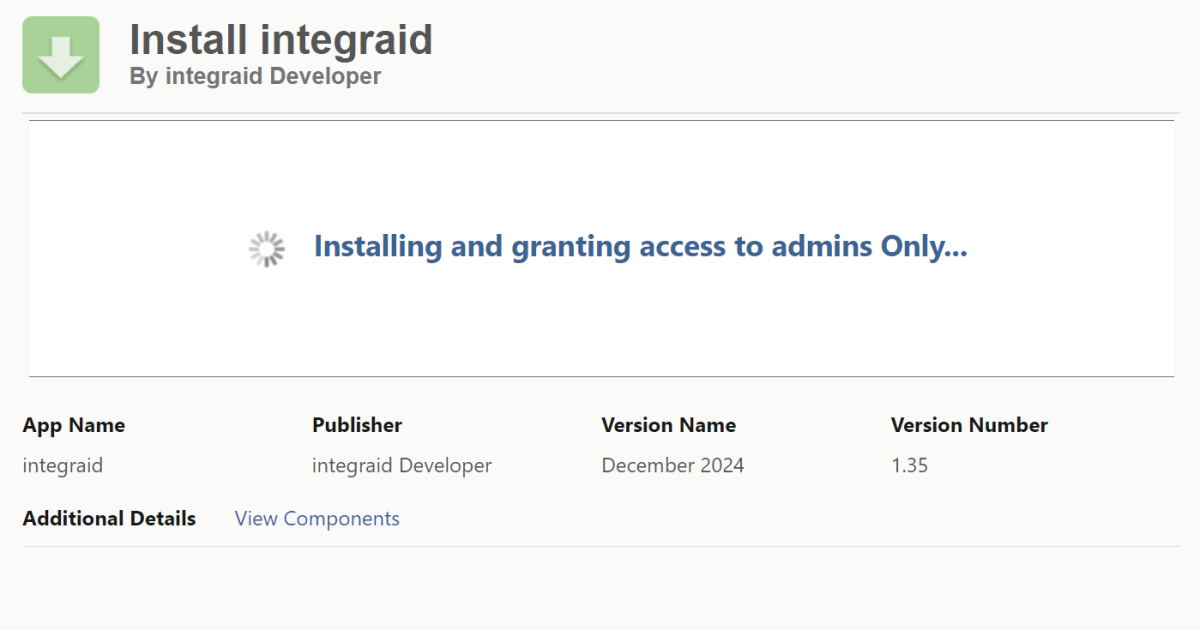
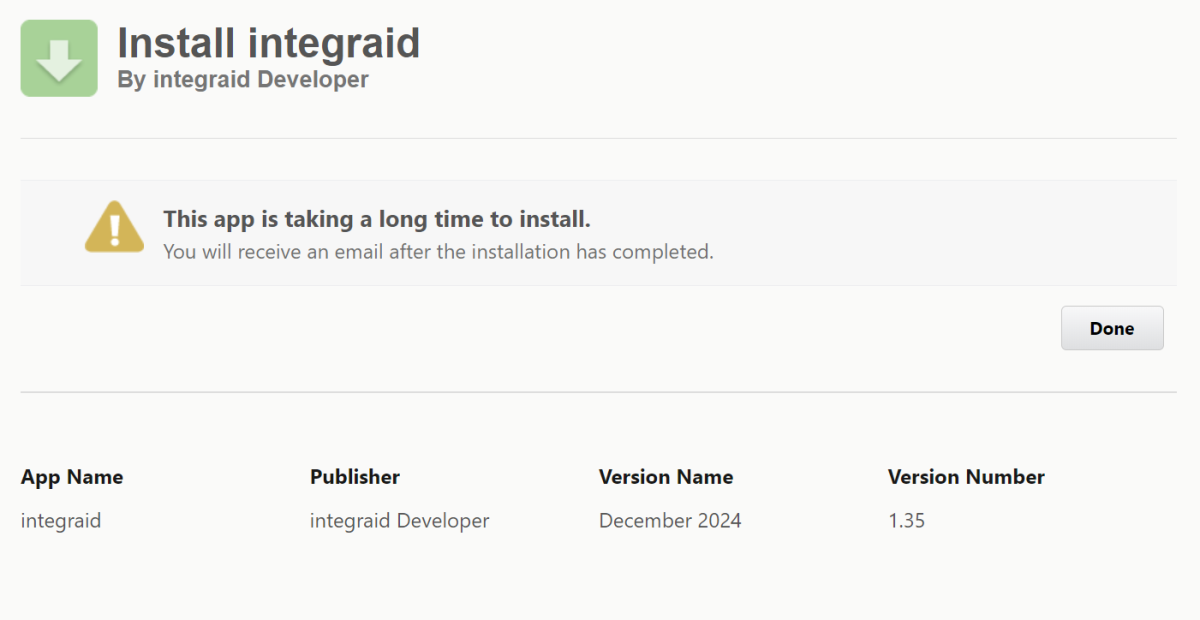
Möglicherweise erscheint eine Benachrichtigung mit folgendem Inhalt: „Die Installation dieser Anwendung nimmt einige Zeit in Anspruch. Sie erhalten eine Email, wenn die Installation abgeschlossen ist.” Wenn eine solche Meldung zum ersten Mal bei dir erscheint, keine Sorge. Klicke einfach auf „Fertig“. Salesforce teilt dir dann per Email mit, wenn die Installation erfolgreich war.
 X
X
Nach Abschluss der Installation empfehlen wir, die Installation im Abschnitt „Pakete“ unter „Installierte Pakete“ in der Salesforce-Einrichtung zu überprüfen.
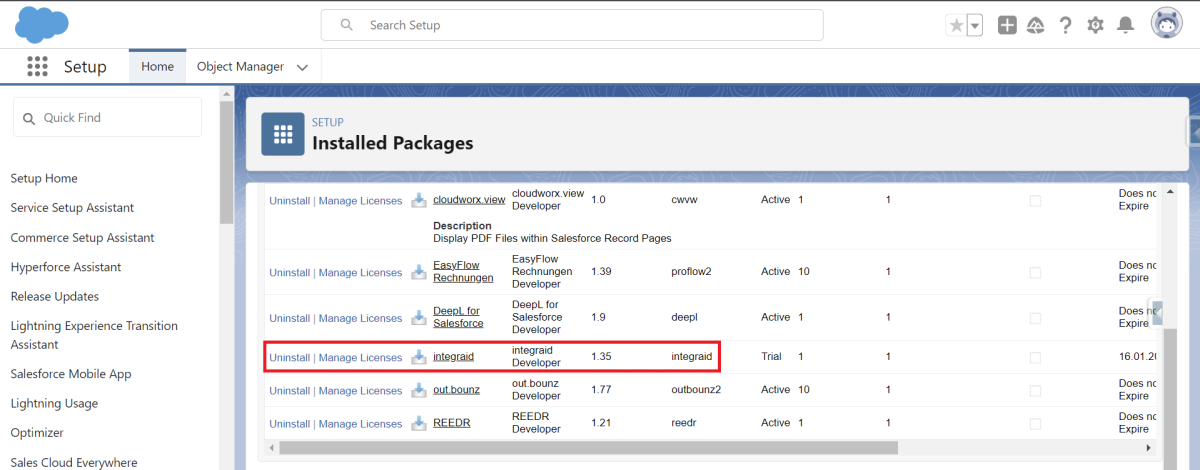 X
X
2.2. Vergabe von Nutzungsrechten
Die Nutzung der Anwendung erfordert keine speziellen Rechte für Salesforce-Benutzer. Lediglich für die Konfiguration und das Debugging müssen Berechtigungen zum Einsehen der integraid-Datensätze vergeben werden. Grundsätzlich wird zwischen zwei Arten von Berechtigungen unterschieden:
- integraid Lizenzen*
- Salesforce Berechtigungssätze*
integraid-Lizenzen werden im Bereich "Installierte Pakete" direkt an dem dort aufgeführten integraid-Paket zugewiesen. Klicke dazu auf den Button "Lizenzen verwalten" und weise die gewünschten Benutzer zu.
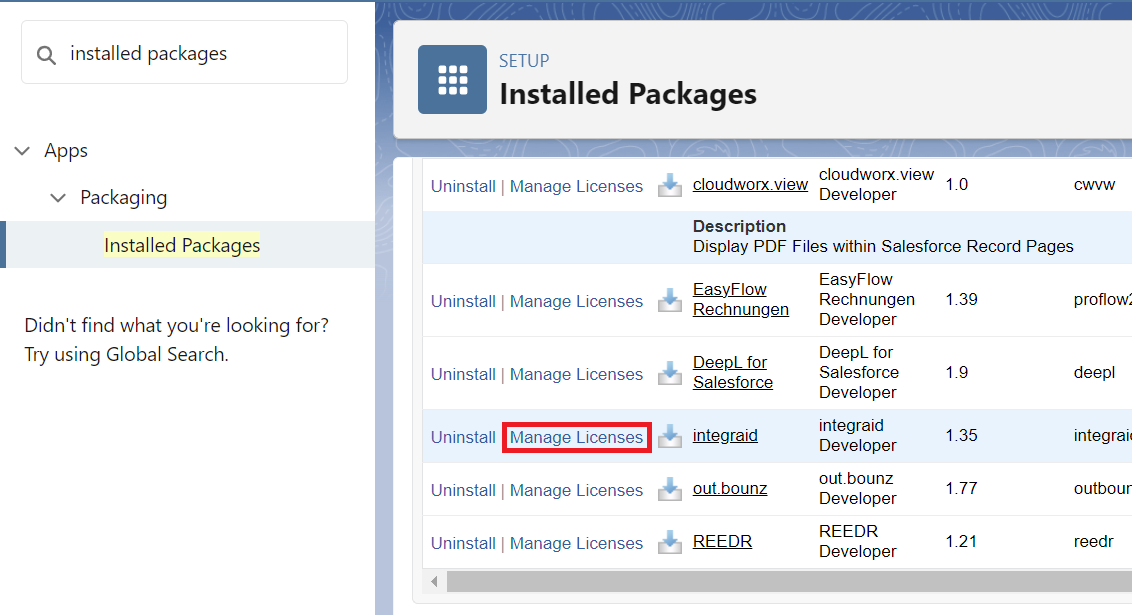 X
X
Die Zuweisung von Salesforce-Berechtigungssets erfolgt hingegen separat. Grundsätzlich werden in integraid die folgenden Typen von Salesforce-Rechtesets unterschieden:
- integraid Admin: für administrativen Vollzugriff auf alle Bereiche der Anwendung.
- integraid User: für den Benutzerzugang.
Um diese Berechtigungssätze zuzuweisen, suche im Setup nach "Berechtigungssätze".
Suche in der Liste nach "integraid Admin" und "integraid User" und klicke auf das jeweilige Set an Rechten, den du einem Benutzer zuweisen möchtest.
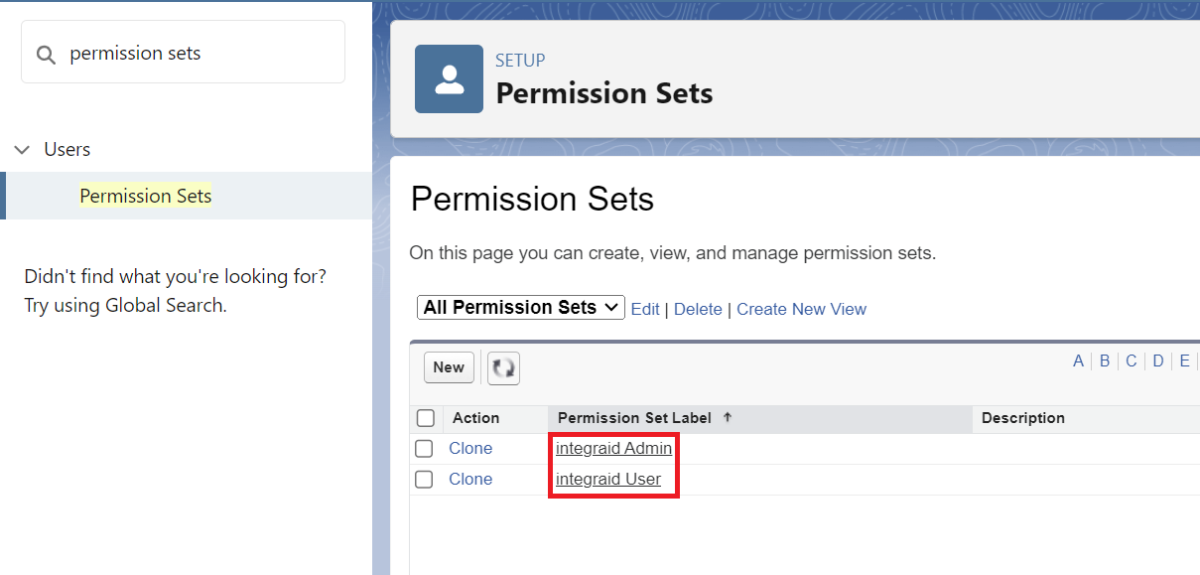 X
X
Gehe auf „Zuweisungen verwalten“ und füge die gewünschten Benutzer mittels Ankreuzen der Checkbox hinzu.
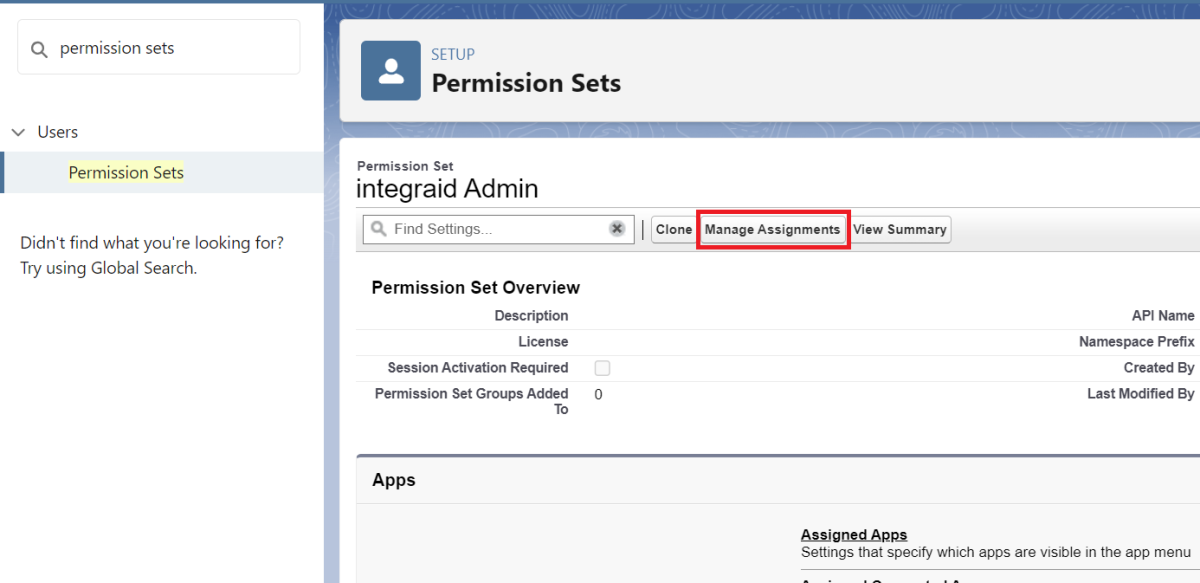 X
X
WICHTIG: Essenziell ist zudem die Freigabe der standardmäßig mit integraid mitgelieferten Dashboards und Reports. Hierzu bitte in die Standard-Tabs für "Reports" und "Dashboards" in der Salesforce-Oberfläche wechseln und dort jeweils (!) in den Freigabeeinstellungen des mit der Installation von integraid hinzugefügten Ordners "integraid" diesen für die Gruppe aller internen Nutzer freigeben. Zu finden ist diese Freigabemöglichkeit folgendermaßen: Suche über die Suchfunktion Berichte bzw. Dashboards > Alle Ordner > integraid > Freigeben (über die Pfeilfunktion rechts). Wird dieser Schritt versäumt, kann der Homescreen der integraid-App für Nutzer ohne Administratorlizenz nicht korrekt dargestellt werden.
2.3. Aktivieren der Record Pages
Da Salesforce bei Installation von Applikationen wie integraid die Aktivierung von Record Pages bei gleichzeitiger Nutzung von Record Types leider nicht zulässt, muss dies nach Installation einmalig manuell erfolgen. Die Aktivierung ist essenziell, um alle Funktionen von integraid vollumfänglich nutzen zu können.
Konkret betrifft dies die Objekte “Scope” und “Record Rule”.
Diese findest du im Setup. Gib hier in der Suchleiste “Lightning App Builder" bzw. "Lightning-Anwendungsgenerator" ein.
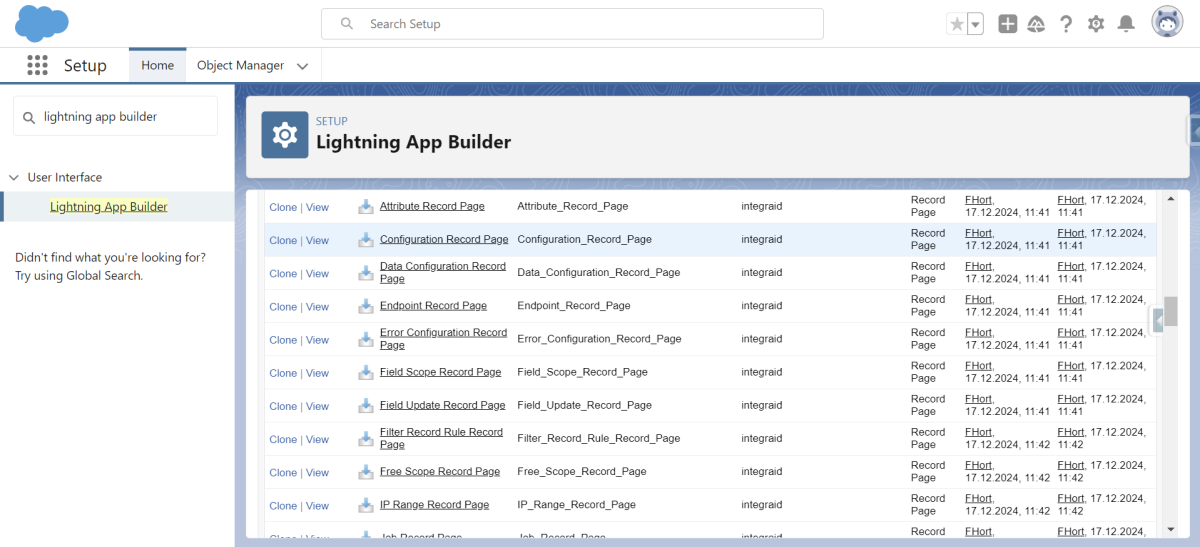 X
X
Die Zuordnung kannst du für die jeweiligen Objekte im Detail wie folgt vornehmen:
Seite anklicken > Anzeigen > Aktivierung > Zu Anwendungen, Datensatztyp und Profilen zuweisen > alle Apps auswählen, die benutzt werden > Weiter > Desktop und Telefon > Weiter > den jeweiligen Record Type auswählen > Weiter > Alle Profile auswählen > Speichern.
Aktiviere folgende Record Pages:
| Objekt | Seite | Record Type |
|---|---|---|
| Scope | Field Scope Record Page | Field |
| Free Scope Record Page | Free | |
| List Scope Record Page | List | |
| Primary Scope Record Page | Primary | |
| Record Rule | Filter Record Rule Record Page | Filter |
| Limit Record Rule Record Page | Limit | |
| Order Record Rule Record Page | Order |
2.4. Konfiguration
Suche im App Launcher* oder über die Suchfunktion die „integraid“-Applikation.
 X
X
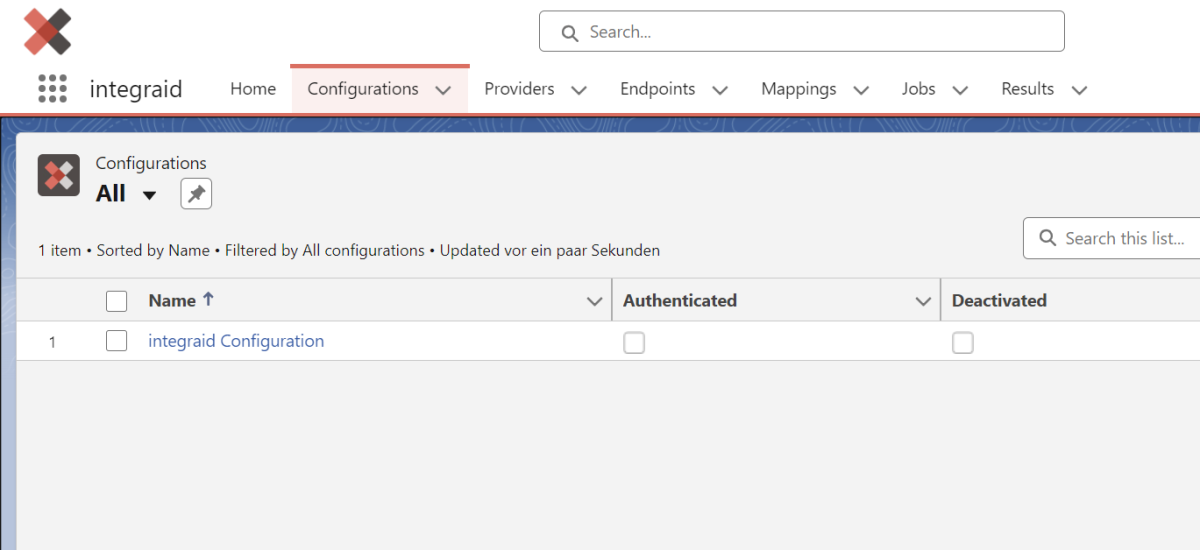
Wechsel in der App direkt in den „Configurations“-Reiter. Hier findest du bereits einen Konfigurations-Datensatz vor. In diesem Datensatz musst du Felder mit den notwendigen Informationen befüllen, um integraid zu konfigurieren.
 X
X
Folgende Felder existieren auf Basis des Konfigurations-Datensatzes:
| Feld | Pflicht | Beschreibung |
|---|---|---|
| Authenticated | Pflichtfeld | Zeigt an, ob integraid mit Salesforce authentifiziert ist. |
| Error Email Address | Optional | In diesem Feld kann eine Email-Adresse angegeben werden, an die im Fehlerfall Benachrichtigungen versendet werden. |
| Request Limit | Optional | Hier kannst du die maximale Anzahl an API-Anfragen definieren, die integraid pro Tag maximal verwenden wird. |
| Deactivated | Optional | Über diese Einstellung kann integraid vollständig deaktiviert werden. Sollte standardmäßig nicht angehakt sein. |
| Debug Mode | Optional | Diese Einstellung dient der erweiterten Ausspielung von Kommunikationsdetails zwischen Salesforce und der externen Schnittstelle. |
2.5. Testversion
Du hast die Möglichkeit, integraid für 30 Tage kostenfrei zu testen und 250 API-Anfragen auszuführen. Du musst dafür keinerlei Kontodaten angeben. Nach 30 Tagen läuft die Testphase automatisch aus und du kannst auf integraid nicht mehr zugreifen.
Falls du integraid in einer Sandbox testen möchtest, funktioniert der Installationsprozess grundsätzlich exakt wie in der Live-Umgebung. Die einzige Ausnahme bildet der Fall, wenn es sich bei der Sandbox um eine Partial Copy handelt, bei der der Konfigurations-Datensatz übertragen wurde. In diesem Fall muss für eine reibungslose Funktion zwingend die Schaltfläche „Reset Configuration“ im Konfigurations-Datensatz genutzt werden.
2.6. Lizenzen buchen
Nachdem du den Konfigurations-Datensatz eingerichtet hast, musst du noch den Kaufprozess abschließen.
Dieser Schritt ist besonders wichtig, damit du integraid nutzen kannst!
Die Lizenzgebühren für die Nutzung von integraid werden per Lastschriftverfahren von dem von dir angegebenen Konto eingezogen. So kannst du deine entsprechenden Informationen hinterlegen:
- In der integraid-App findest du auf Ebene des Konfigurations-Datensatzes den Button "Manage Licenses". Klickst du auf den Button, öffnet sich eine Login-Seite zu deinem License-Management-Bereich. In diesem Kundenportal findest du alle wichtigen Daten zu deinen integraid-Lizenzen, Zahlungsinformationen, aber auch die Möglichkeit, per Klick weitere Lizenzen hinzuzubuchen.
- Um dich einzuloggen, erhältst du per Email einen individuellen Code, den du zum - Anmelden in der Login-Maske eingibst. Nach dem Login öffnet sich die Übersichtsseite mit einigen Hinweisen, welche Informationen du uns mitteilen musst, damit du integraid in Zukunft nutzen kannst.
- Indem du auf "Check your billing address" klickst, kannst du eine gültige Rechnungsadresse hinterlegen. Klicke anschließend auf "Check your SEPA direct debit mandate", um ein gültiges SEPA-Lastschriftmandat zu erteilen. Du findest die Eingabemasken für deine Daten auch unten in den Reitern "Billing" und "Payment".
Nachdem du die notwendigen Daten eingegeben und gespeichert hast, erhältst du von uns per Email eine Bestätigung und ein Dokument mit allen Informationen zu deinem SEPA-Lastschriftmandat.
Beachte: Die Email mit der Bestätigung wird an die Email-Adresse gesendet, die beim integraid-Download im Salesforce AppExchange angegeben wurde! Sollte diese Email nicht verfügbar sein, schreibe uns einfach eine Nachricht an support@integraid.com.
 X
X
2.7. Authentifizierung
Sobald der Konfigurations-Datensatz erstellt ist, musst du dich bei den integraid-Servern authentifizieren, um alle verfügbaren Funktionen zu nutzen.
Diese Authentifizierung wird einmalig durchgeführt. Klicke dazu einfach auf die Schaltfläche "Authenticate" im erstellten Datensatz.
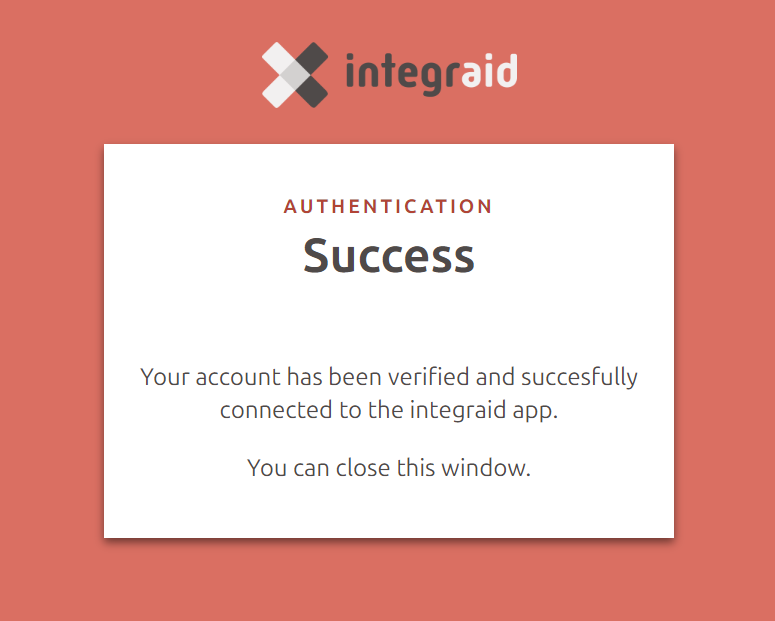
Nach erfolgreicher Authentifizierung (die ggf. durch Bestätigung der OAuth2-Abfrage abgeschlossen werden muss), wird der Nutzer auf eine Ergebnisseite weitergeleitet. Bei erfolgreicher Authentifizierung wird diese durch ein Häkchen im Feld "Authentifiziert" angezeigt.
Im Falle einer erfolgreichen Authentifizierung erscheint zudem die folgende Meldung:
 X
X
Hinweis: Für erweiterte Sicherheit empfehlen wir dringend, IP-Bereiche für die Anmeldung für das Profil des Integration Users (der Benutzer, der sich authentifiziert) zu aktivieren. Dadurch wird der Zugriff auf diesen Benutzer auf lediglich unseren Server beschränkt. Die zu definierenden IP-Adressbereiche sind:
- Von & Bis IP-Adresse: 92.205.105.248
- Von & Bis IP-Adresse: 2a00:1169:11d:7b40::
3. Operative Nutzung von integraid
In diesem Kapitel beschreiben wir, wie du den größten Nutzen aus integraid ziehen kannst. Auch hierzu sind konfigurative Maßnahmen nötig, die - wie auch die bereits erledigten Konfigurationen - nur einmalig ausgeführt werden müssen.
Wir zeigen dir die Einstellungen anhand von Use Cases, um die Konfiguration anschaulicher zu gestalten. Natürlich kannst du integraid für deinen ganz individuellen Use Case und mit deinen eigenen Custom Objects konfigurieren und nutzen.
3.1. Providers
Ein Provider ist die Basis-URL der API, die wir ansprechen wollen. Einen Provider kannst du hinzufügen, indem du auf den Button “New” oben rechts im Reiter “Providers” klickst.
Eine Oberfläche zur Erstellung eines “Provider”- Datensatzes öffnet sich. Fülle folgende Felder für die Konfiguration aus:
| Feld | Pflicht | Beschreibung |
|---|---|---|
| Name | Pflichtfeld | Eigener, frei wählbarer Name des Providers. |
| Base URL | Optional | Hier trägst du die Basis-URL der API ein, die angesprochen werden soll. |
Hinweis: Wird keine Basis-URL im Provider definiert, muss die gesamte URL in den Endpunkten angegeben werden.
Nun musst du per Klick auf den Button “Authorization” die Autorisierung gegenüber der API konfigurieren. Du kannst zwischen “URL”,”Basic”,”Token” oder “OAuth 2.0” Autorisierung wählen. Über welches Verfahren die API autorisiert werden soll, findest du in der jeweiligen Schnittstellendokumentation.
3.1.1. URL
Die URL-Autorisierung erfolgt durch Anhängen eines API-Schlüssels direkt als Parameter an die URL.
Es gibt folgende Felder:
| Feld | Beschreibung |
|---|---|
| Appendix | In diesem Feld gibst du den Parameter ein, mit dem der API-Schlüssel übergeben wird, z.B. api_key=<API-Schlüssel>. |
3.1.2. Basic
Die Basic-Authentifizierung nutzt eine Kombination aus Benutzername und Passwort für den Zugriff auf die API.
Es gibt folgende Felder:
| Feld | Beschreibung |
|---|---|
| Username | Gib hier den Benutzernamen für den API-Zugriff ein. |
| Password | Trage das zugehörige Passwort ein. |
3.1.3. Token
Diese Methode verwendet einen Token, der im Header der API-Anfrage gesendet wird.
Token Type: Wähle hier den Datentyp des Tokens aus (String oder JWT).
Es gibt folgende Felder, wenn als Token Type String gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header | Der Name des HTTP-Headers, unter dem der Token gesendet wird, bspw. Authorization. |
| Header Prefix | Optionales Präfix, das vor dem eigentlichen Token steht, z.B. Bearer. |
| Token | Der feste Zugriffstoken (z. B. API-Key oder Auth-Token), der bei jeder Anfrage mitgesendet wird. |
Es gibt folgende Felder, wenn als Token Type JWT gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header | Der Name des HTTP-Headers, unter dem der Token gesendet wird, bspw. Authorization. |
| Header Prefix | Optionales Präfix, das vor dem eigentlichen Token steht, z.B. Bearer. |
| Issuer | Der "Aussteller" des Tokens – also wer den Token erstellt. In JWTs oft ein eindeutiger Identifikator wie eine Client-ID oder ein Domainname. |
| Subject | Der "Nutzer", für den der Token ausgestellt wird. Das kann z. B. eine Benutzer-ID oder ein Systemname sein. |
| Audience | Die Zielgruppe des Tokens, also für welchen Dienst/API der Token gedacht ist. |
| Algorithm | Bestimmt das Verfahren zur Signierung des JWT. HS256–512 verwenden einen gemeinsamen Secret-Key (HMAC), RS256–512 nutzen ein asymmetrisches RSA-Schlüsselpaar. |
| Private Key | Wird zur Signierung des JWT verwendet. Bei HS: einfacher Secret-Text. Bei RS: unverschlüsselter Private Key im PKCS#8-Format (kein Passwortschutz). |
3.1.4. OAuth 2.0
OAuth 2.0 ist ein komplexeres Verfahren, das sich für APIs mit erhöhtem Sicherheitsbedarf eignet und erweiterte Autorisierungsfunktionen bietet.
Es gibt folgende Felder, wenn als Grant Type “Authorization Code” gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header Prefix | Präfix für den Access Token im Header, z. B. Bearer. |
| Token URL | URL des OAuth-Servers, bei dem der Access Token unter Angabe von Username und Passwort angefordert wird. |
| Refresh URL | URL zur Erneuerung des Access Tokens mittels Refresh Token. |
| Authorize URL | URL, zu der der Benutzer für die initiale Autorisierung weitergeleitet wird. |
| Use PKCE | Aktivieren, wenn der Authorization Code Flow mit PKCE verwendet wird – empfohlen bei mobilen Anwendungen. |
| Client Id | Die Client-ID deiner Anwendung – wird vom API-Anbieter bereitgestellt. |
| Client Secret | Das Client-Geheimnis (Passwort), das zur Authentifizierung deines Clients verwendet wird. |
| Credentials Location | Gibt an, wo Client Id und Client Secret beim Token Request übertragen werden: im Body oder im Header. |
| Scope | Gibt an, auf welche Ressourcen die API Zugriffsrechte hat. Wird meist von großen API-Anbietern verwendet. Es können mehrere Scopes durch Leerzeichen getrennt angegeben werden. |
| Appendix | Optionales Feld für zusätzliche Parameter. |
Es gibt folgende Felder, wenn als Grant Type “Client Credentials” gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header Prefix | Präfix für den Access Token im Header, z. B. Bearer. |
| Token URL | URL des OAuth-Servers, bei dem der Access Token unter Angabe von Username und Passwort angefordert wird. |
| Refresh URL | URL zur Erneuerung des Access Tokens mittels Refresh Token. |
| Client Id | Die Client-ID deiner Anwendung – wird vom API-Anbieter bereitgestellt. |
| Client Secret | Das Client-Geheimnis (Passwort), das zur Authentifizierung deines Clients verwendet wird. |
| Credentials Location | Gibt an, wo Client Id und Client Secret beim Token Request übertragen werden: im Body oder im Header. |
| Scope | Gibt an, auf welche Ressourcen die API Zugriffsrechte hat. Wird meist von großen API-Anbietern verwendet. Es können mehrere Scopes durch Leerzeichen getrennt angegeben werden. |
| Appendix | Optionales Feld für zusätzliche Parameter. |
Es gibt folgende Felder, wenn als Grant Type “JWT” gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header Prefix | Präfix für den Access Token im Header, z. B. Bearer. |
| Token URL | URL des OAuth-Servers, bei dem der Access Token unter Angabe von Username und Passwort angefordert wird. |
| Refresh URL | URL zur Erneuerung des Access Tokens mittels Refresh Token. |
| Client Id | Die Client-ID deiner Anwendung – wird vom API-Anbieter bereitgestellt. |
| Client Secret | Das Client-Geheimnis (Passwort), das zur Authentifizierung deines Clients verwendet wird. |
| Credentials Location | Gibt an, wo Client Id und Client Secret beim Token Request übertragen werden: im Body oder im Header. |
| Issuer | iss-Feld im JWT – bezeichnet die ausstellende Entität (z. B. die Client-ID). |
| Subject | sub-Feld im JWT – identifiziert den Benutzer oder die Entität, für die das Token ausgestellt wird. |
| Audience | aud-Feld im JWT – gibt an, für welchen Empfänger (z. B. Token-Server) das JWT bestimmt ist. |
| Algorithm | Gibt an, welcher Signaturalgorithmus zum Signieren des JWT verwendet wird. |
| Private Key | Schlüssel zur Signierung des JWT. |
| Scope | Gibt an, auf welche Ressourcen die API Zugriffsrechte hat. Wird meist von großen API-Anbietern verwendet. Es können mehrere Scopes durch Leerzeichen getrennt angegeben werden. |
| Appendix | Optionales Feld für zusätzliche Parameter. |
Es gibt folgende Felder, wenn als Grant Type “Password” gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header Prefix | Präfix für den Access Token im Header, z. B. Bearer. |
| Token URL | URL des OAuth-Servers, bei dem der Access Token unter Angabe von Username und Passwort angefordert wird. |
| Refresh URL | URL zur Erneuerung des Access Tokens mittels Refresh Token. |
| Client Id | Die Client-ID deiner Anwendung – wird vom API-Anbieter bereitgestellt. |
| Client Secret | Das Client-Geheimnis (Passwort), das zur Authentifizierung deines Clients verwendet wird. |
| Credentials Location | Gibt an, wo Client Id und Client Secret beim Token Request übertragen werden: im Body oder im Header. |
| Username | Benutzername des Users, für den der Access Token ausgestellt werden soll. |
| Password | Passwort des Users. |
| Scope | Gibt an, auf welche Ressourcen die API Zugriffsrechte hat. Wird meist von großen API-Anbietern verwendet. Es können mehrere Scopes durch Leerzeichen getrennt angegeben werden. |
| Appendix | Optionales Feld für zusätzliche Parameter. |
Es gibt folgende Felder, wenn als Grant Type “Refresh Token” gewählt wird:
| Feld | Beschreibung |
|---|---|
| Header Prefix | Präfix für den Access Token im Header, z. B. Bearer. |
| Token URL | URL des OAuth-Servers, bei dem der Access Token unter Angabe von Username und Passwort angefordert wird. |
| Refresh URL | URL zur Erneuerung des Access Tokens mittels Refresh Token. |
| Client Id | Die Client-ID deiner Anwendung – wird vom API-Anbieter bereitgestellt. |
| Client Secret | Das Client-Geheimnis (Passwort), das zur Authentifizierung deines Clients verwendet wird. |
| Credentials Location | Gibt an, wo Client Id und Client Secret beim Token Request übertragen werden: im Body oder im Header. |
| Refresh Token | Der vorhandene Refresh Token, der für die Erneuerung des Access Tokens verwendet wird. |
| Scope | Gibt an, auf welche Ressourcen die API Zugriffsrechte hat. Wird meist von großen API-Anbietern verwendet. Es können mehrere Scopes durch Leerzeichen getrennt angegeben werden. |
| Appendix | Optionales Feld für zusätzliche Parameter. |
Auf Ebene des Providers kannst du weiterhin “IP Ranges” und “Error Configurations” konfigurieren. Die Konfiguration dieser Elemente ist jedoch optional.
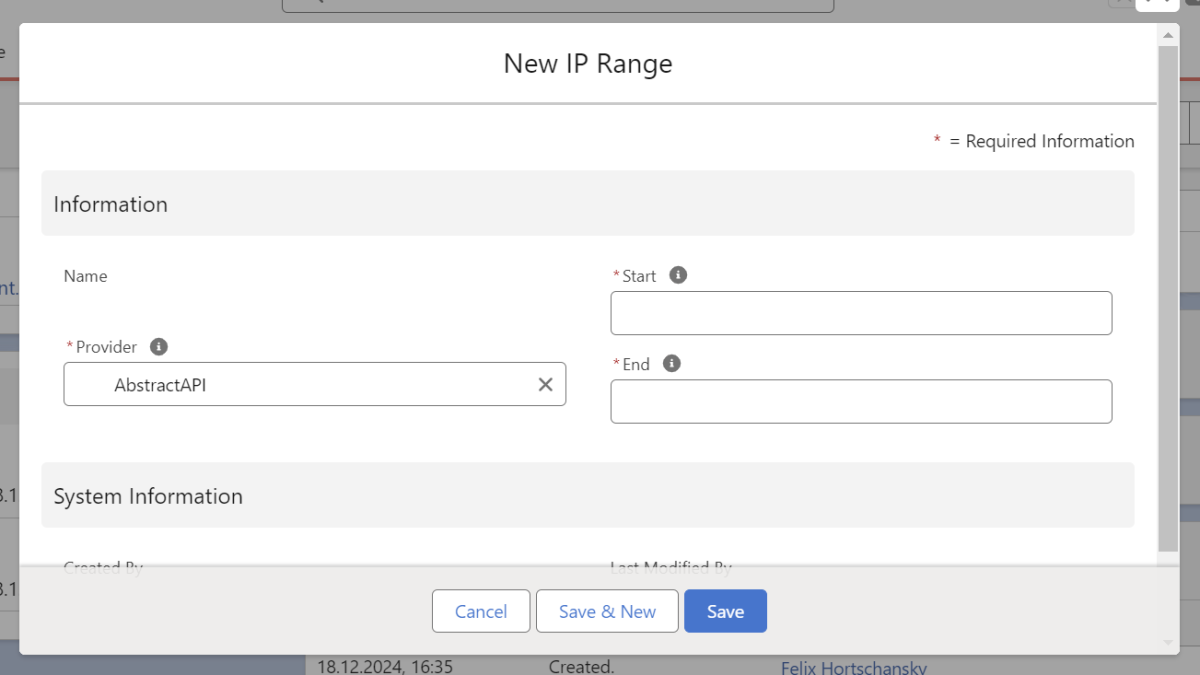
3.1.5. IP Ranges
IP Ranges dienen als IP-Filter, um die Sicherheit bei der Integration von Drittsystemen in Salesforce über integraid zu erhöhen. Du kannst Start- und End-IP-Adressen angeben, um einen bestimmten Bereich von IP-Adressen zu definieren.
 X
X
Versucht ein Server, außerhalb der definierten IP Ranges auf das System zuzugreifen, wird der Zugriff automatisch verweigert. Es können jedoch mehrere IP-Bereiche festgelegt werden, und der Zugriff wird gewährt, sofern die IP-Adresse in mindestens einem dieser Bereiche liegt. Wenn keine IP-Ranges definiert sind, bleibt der Zugriff für alle IP-Adressen standardmäßig erlaubt.
3.1.6. Cookies
Im Bereich "Cookies" werden Cookies, die während der Kommunikation mit einem Provider empfangen werden, automatisch gespeichert. Ein Cookie-Datensatz enthält die folgenden Felder:
| Feld | Beschreibung |
|---|---|
| Name | Eigener, frei wählbarer Name für den Cookie |
| Provider | Verweis auf den zugehörigen Provider |
| Domain | Definiert, welcher Server den Cookie empfangen darf. Dazu zählen unter anderem auch alle Subdomains der hier spezifizierten Domain. |
| Path | Legt den URL-Pfad fest, an welchen der Cookie gesendet werden soll. |
| Expiration | Definiert die Ablaufzeit des Cookies. |
| Secure | Ist das Kästchen angehakt, wird der Cookie nur bei sicheren Anfragen (über HTTPS-Protokoll) gesendet. |
| Value | Hier wird der tatsächliche Wert des Cookies gespeichert. |
Cookies müssen nicht manuell konfiguriert werden, sondern werden automatisch gespeichert, wenn sie in einer API-Antwort definiert sind. Sobald ein Cookie in Integraid gespeichert ist, wird er an alle Callouts mit der zugehörigen URL und dem zugehörigen Pfad angehängt. Wenn der Cookie abläuft, wird er automatisch gelöscht.
Hinweis: Die Implementierung von Cookies durch Integraid orientiert sich an folgendem Leitfaden: https://developer.mozilla.org/en-US/docs/Web/HTTP/Guides/Cookies. Die Parameter „HttpOnly” und „SameSite” werden nicht gespeichert, da sie keinen Einfluss auf die Kommunikation in Integraid haben.
3.1.7. Fehler Konfiguration
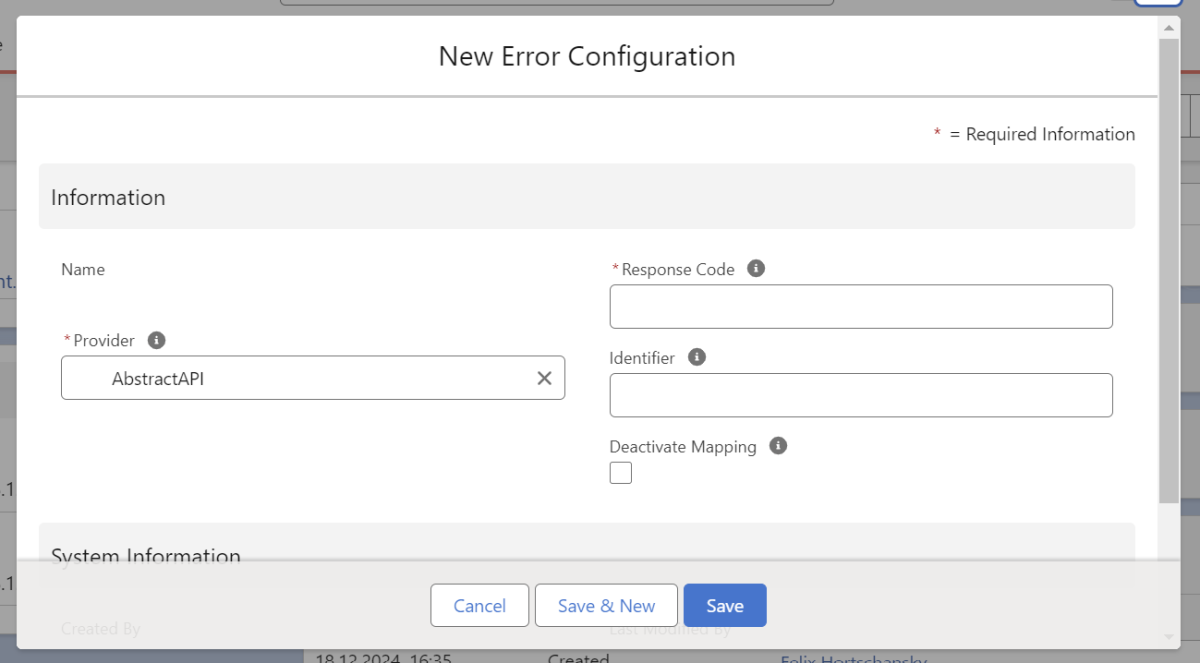
Error Configurations dienen dem Error Handling und legen fest, welche HTTP-Response Codes als Fehler gewertet werden sollen.
 X
X
In dem Feld “Response Code” können entweder spezifische Response-Codes definiert werden, oder allgemeine Code-Bereiche, wie alle Codes, die mit “4” beginnen. 400er-Response-Codes können so beispielsweise als Fehler oder auch als zulässige Antwort interpretiert werden, während 500er-Codes immer als Fehler behandelt werden.
Hinweis: Wenn die Fehlermeldung "Zugriff verweigert" oder etwas Ähnliches mit einem 500er-Fehler auftritt, kann dies an der URL liegen. Stelle sicher, dass "https://" oder "http://" in der URL enthalten ist. Eventuell muss auch das Protokoll (http:// oder https://) in den Provider aufgenommen werden bzw. in den Endpunkt, falls die Basis-URL des Providers leer ist.
Über das Feld “Identifier” kann außerdem der Identifier des Knotens in der Antwort definiert werden, der die Fehlermeldung enthält, z. B. „Message“ oder „Error“. Dieser Identifier wird verwendet, um Fehler in den Ergebnissen und für den User eindeutig zurückzuspielen.
Außerdem lässt sich über die Checkbox “Deactivate Mapping” festlegen, ob der in der Konfiguration definierter Fehler dazu führen soll, dass bei wiederholtem Auftreten das Mapping deaktiviert wird.
3.2. Endpoints
Nach Erstellung des Providers können ein oder mehrere Endpunkte erstellt werden. Der Endpunkt ist der Service der API, der angesprochen werden soll. Einen Endpunkt kannst du hinzufügen, indem du auf den Button “New” oben im Reiter “Endpoints” klickst.
Eine Oberfläche zur Erstellung eines Endpoint-Datensatzes öffnet sich. Fülle folgende Felder für die Konfiguration aus:
| Feld | Pflicht | Beschreibung |
|---|---|---|
| Name | Pflichtfeld | Eigener, frei wählbarer Name des Endpunktes. |
| Provider | Optional | Name des Providers, zu dem der Endpunkt gehört. |
| Type | Pflichtfeld | Indiziert den Typ* des Endpunkts. |
| Method | Pflichtfeld | Spezifiziert die HTTP-Methode*, mit welcher der Endpunkt angesprochen wird. |
| URL | Pflichtfeld | Enthält die Endpunkt-URL. Dies kann eine vollständige URL oder nur der Endpunkt sein. Wenn keine vollständige URL angegeben ist, wird die Basis-URL des Anbieters vorangestellt. Hier kann auch mit sogenannten Merge-Feldern* gearbeitet werden. |
3.2.1. Typen von Endpunkten
Zuerst muss der Typ des Endpunkts festgelegt werden. Der Type bestimmt die Art und Weise, wie die Kommunikation zwischen Salesforce und Drittsystemen abläuft. Er definiert, ob eine Anfrage synchron oder asynchron erfolgt, und wie die Antwort behandelt wird. Hierbei wird zwischen 4 Types unterschieden:
- Callout: Der Callout ist ein synchroner Prozess, bei dem integraid eine Anfrage an ein Drittsystem sendet und sofort eine Antwort erhält. Die Transaktion gilt mit dem Empfang der Antwort als abgeschlossen.
- Async Callout: Der Async Callout ermöglicht eine asynchrone Kommunikation, bei der eine Anfrage gesendet und eine Callback-URL für die spätere Übermittlung der Antwort angegeben wird. Die Antwort erfolgt zu einem späteren, unbestimmten Zeitpunkt.
- Callin: Der Callin ermöglicht es einem Drittsystem, integraid bei bestimmten Ereignissen zu benachrichtigen, ähnlich einem Webhook. Die Benachrichtigungen können mehrfach und zu unterschiedlichen Zeitpunkten ohne vorherige Anfrage erfolgen. Zudem können HTML-Formulare Daten an Endpunkte dieses Typs senden.
- Forced Async Callout: Der Forced Async Callout führt einen gegenüber der Schnittstelle synchronen Callout Salesforce-seitig asynchron aus. Dies umgeht Salesforce-Limits und ermöglicht somit längere Callouts in Salesforce. Wir empfehlen die Verwendung dieses Typs ausschließlich beim Auftreten von Salesforce-Fehlern auf Grund erreichter Salesforce-Limits.
3.2.2. HTTP Methoden
HTTP Methoden werden verwendet, um Anfragen an einen Server zu stellen. Jede Methode hat eine spezifische Funktion, die beschreibt, welche Art von Operation auf einer Ressource durchgeführt werden soll. Hier eine Übersicht:
- Die GET-Methode wird genutzt, um Daten der Schnittstelle abzufragen, ohne diese zu verändern. Diese Methode liefert bei wiederholten Anfragen stets dieselben Ergebnisse, solange die Daten auf Seiten der Schnittstelle unverändert bleiben.
- Die POST-Methode dient dazu, neue Datensätze in Salesforce zu erstellen oder Aktionen wie Trigger auszuführen. Wiederholte Anfragen können zu mehrfacher Erstellung von Datensätzen oder mehrfacher Ausführung von Prozessen führen.
- Die PUT-Methode wird verwendet, um Datensätze in Salesforce zu erstellen oder vollständig zu aktualisieren. Bei jeder Anfrage wird der Datensatz in Salesforce durch die übermittelten Daten ersetzt, sodass das Ergebnis konsistent bleibt.
- Die PATCH-Methode wird eingesetzt, um vorhandene Datensätze in Salesforce gezielt zu aktualisieren. Nur die angegebenen Felder werden geändert, was diese Methode besonders effizient für inkrementelle Updates macht.
- Die DELETE-Methode ermöglicht das Löschen von Datensätzen in Salesforce. Ein erneutes Senden der Anfrage hat keine zusätzlichen Auswirkungen, da der Datensatz nach der ersten Anfrage bereits entfernt ist.
Welche HTTP-Methode für deinen Anwendungsfall benötigt wird, siehst du in der Schnittstellendokumentation des Providers.
Anschließend musst du den Endpunkt per Klick auf den “Configure”-Button konfigurieren. Hierbei konfigurierst du die Struktur ausgehender und eingehender Daten (outbound, inbound).
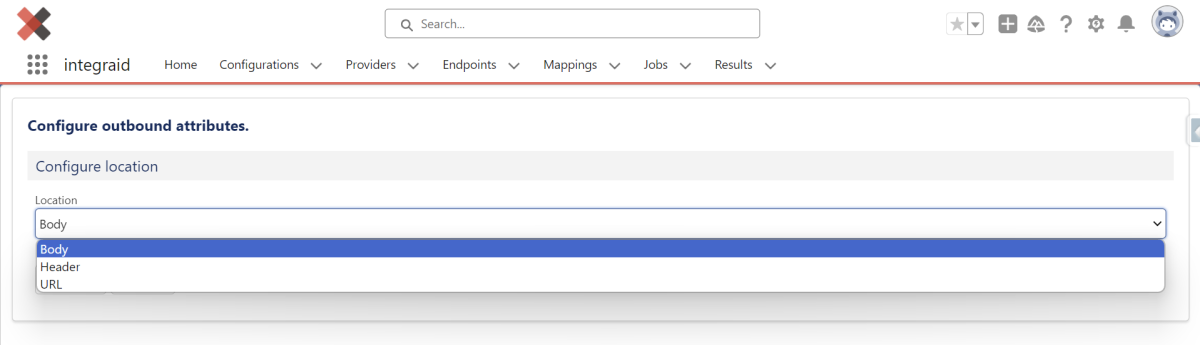
3.2.3. Outbound
Zuerst legst du fest, wo die Information enthalten ist, welche du aus deinem Salesforce System an die Schnittstelle übermitteln willst. Hierbei hast du die Optionen “Body”, “Header” und “URL”. Das sind die Orte, an denen die Daten übermittelt werden können.
 X
X
Body
Wenn du „Body“ als Attribut auswählst, werden die zu sendenden Daten im Nachrichtenkörper der HTTP-Anfrage übertragen.
- Content Type: Du kannst das Format der Nachricht bestimmen, z. B. application/json, application/xml oder andere Formate, je nach Anforderung der Schnittstelle.
- Quantity: Hier wird festgelegt, ob ein einzelnes Datenelement (Single) oder mehrere Elemente (Array) übertragen werden sollen.
- Type: Es wird zwischen Node und Value unterschieden:
- Node: eine Struktur mit Unterelementen.
- Value: ein einzelner Wert.
Unterhalb des Bodys kannst du einzelne Felder oder verschachtelte Strukturen anlegen, die aus Salesforce-Daten befüllt werden.
Über die Funktion „Import“ kannst du außerdem eine Beispielstruktur (z. B. JSON) hochladen, wodurch die Felder automatisch erstellt werden.
Typische Anwendungsfälle für Body sind:
- Senden von Datensätzen an REST-APIs (z. B. POST neuer Leads oder Opportunities).
- Übertragen von komplexen JSON-Objekten.
Hinweis: Für den Transfer von Dokumenten an externe Schnittstellen unterstützt integraid lediglich Files (ContentDocuments) und keine Attachments. Falls bei Dokumententransfers Fehler auftreten sollten, überprüfe die Art des Dokuments, da diese Unterscheidung den Fehler auslösen könnte.
Header
Wenn du „Header“ auswählst, werden die Salesforce-Daten in die HTTP-Header der Anfrage eingefügt.
- Quantity: Auch hier definierst du, ob Einzelwerte oder Arrays gesendet werden.
- Type: Auch Header können in einfache Schlüssel-Wert-Paare (Value) oder in strukturierte Nodes unterteilt werden.
Header werden genutzt, um:
- Authentifizierungsinformationen zu senden (z. B. API-Keys, Bearer Tokens).
- Spezielle Steuerinformationen an die API zu übermitteln (z. B. Content-Type Header).
Wie bei Body kannst du auch hier Child-Elemente (Felder) hinzufügen, um dynamische Headerfelder aufzubauen.
URL
Bei Auswahl von „URL“ werden Daten als Parameter an die URL der API angehängt (Query-Parameter).
- Quantity: Einzelwerte (Single) oder Listen (Array) sind möglich.
- Type: Definiert, ob der Parameter als Node oder Value behandelt wird.
Bei URL-Parametern kannst du:
- Statische Werte definieren.
- Felder aus Salesforce dynamisch in die URL übernehmen (z. B. Domain, ID, Status).
- Arrays als kommaseparierte Parameter aufbauen.
Die URL-Parameter werden automatisch korrekt formatiert (?key1=value1&key2=value2) und an die Endpunkt-URL angehängt.
Typische Anwendungsfälle für URL-Parameter sind:
- GET-Requests mit Filter- oder Suchkriterien.
- Identifizierung einer Ressource über die URL.
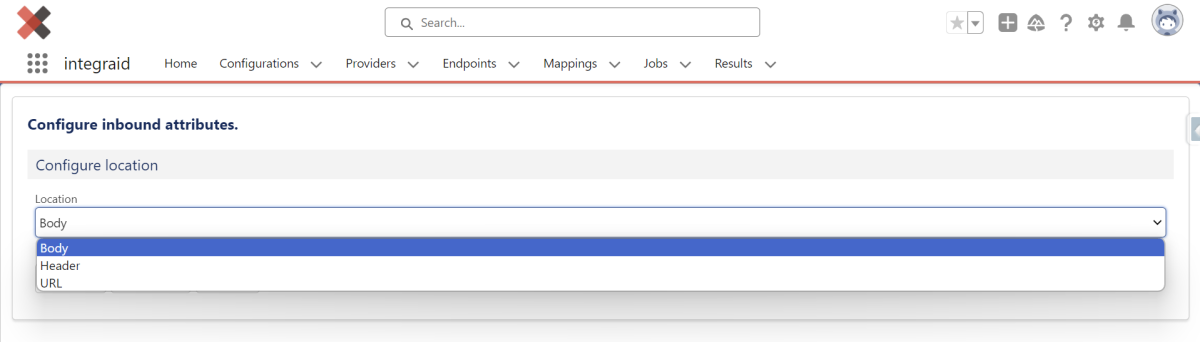
3.2.4. Inbound
Als nächstes legst du fest, welche Information du von der Schnittstelle erhalten wirst. Die Inbound-Konfiguration befasst sich damit, in welcher Struktur das System Daten von einer Schnittstelle empfängt. Hierbei hast du ebenfalls die Optionen “Body”, “Header” und “URL”.
 X
X
Body
Wenn du „Body“ auswählst, verarbeitet integraid die Inhalte aus dem Nachrichtenkörper der API-Antwort.
- Content Type: Du gibst das erwartete Format an, z. B. application/json, application/xml, etc. Dadurch weiß integraid, wie die Antwortstruktur gelesen werden soll.
- Type: Es wird festgelegt, ob die Daten als Node (komplexe Struktur) oder Value (einzelner Wert) interpretiert werden.
Im Body kannst du beliebig viele Attribute (Datenfelder) anlegen:
- Jedes Attribut erhält einen Identifier (Name aus der API).
- Du legst den Datentyp fest, z. B. String, Number, Boolean oder Date.
- Du kannst die Struktur selbst definieren oder automatisch über die Importfunktion aus einer Beispielantwort erzeugen.
Typische Nutzung:
- Übernahme komplexer JSON- oder XML-Responses mit verschachtelten Elementen.
- Extrahieren mehrerer Datenfelder (z. B. Firmenname, Umsatz, Standort).
Header
Bei Auswahl von „Header“ liest integraid die Informationen direkt aus den HTTP-Headern der Antwort.
- Type: Auch hier kannst du Node oder Value verwenden, je nachdem, ob einfache oder strukturierte Daten verarbeitet werden.
In der Konfiguration gibst du an:
- Welche Header-Felder ausgewertet werden sollen.
- Welche Typen die Header-Daten haben (z. B. String, Boolean).
Typische Nutzung:
- Verarbeitung von Authentifizierungsdaten oder Systeminformationen, die im Header transportiert werden.
- Auslesen von Statusinformationen (z. B. Tokens, Session-IDs).
URL
Wenn „URL“ gewählt wird, verarbeitet integraid Parameter oder Informationen, die in der URL der Antwort enthalten sind.
- Type: Auch URL-Parameter können als einfache Werte (Value) oder komplexe Strukturen (Node) aufgebaut sein.
Hier definierst du:
- Welche URL-Parameter ausgewertet werden sollen (z. B. ID, Status).
- Wie die Daten ausgelesen und weiterverarbeitet werden.
Typische Nutzung:
- APIs, die Zustände oder IDs über die URL zurückgeben.
- Abruf von Ergebnissen über Redirects oder Query-Strings.
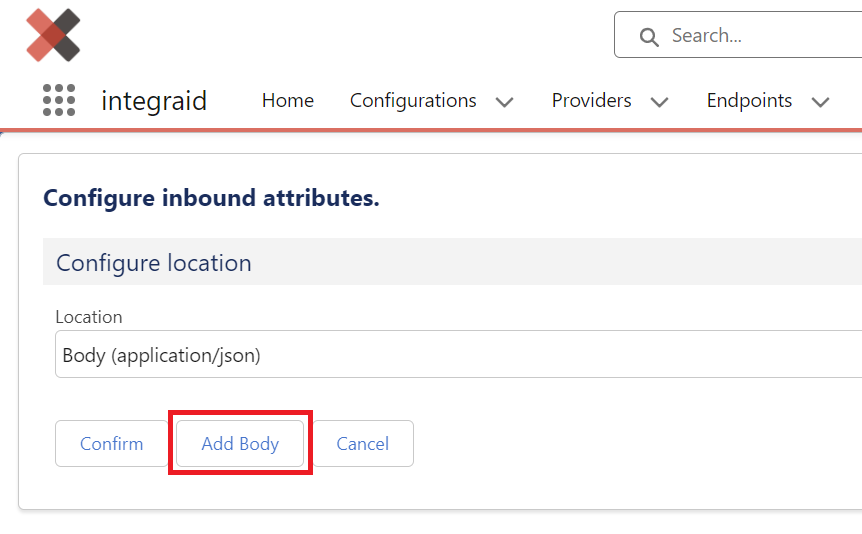
Button “Add Body”
Der Button “Add Body” ermöglicht es, alternative Antwort-Bodies zu definieren. Dies ist besonders wichtig, wenn Schnittstellen im Erfolgsfall und im Fehlerfall unterschiedliche Content Types zurückliefern. So kann es beispielsweise sein, dass im Erfolgsfall eine Datei als Binärdaten (Octet-Stream) zurückgegeben wird, während im Fehlerfall JSON-Daten geliefert werden.
 X
X
Durch Klicken auf "Add Body" kann man einen der verbleibenden Content Types auswählen und eine individuelle Antwortstruktur definieren. integraid verwendet den von der Schnittstelle mitgelieferten Content Type, um die richtige Richtung für die Antwortverarbeitung einzuschlagen.
3.3. Mappings
Nachdem du dem System beigebracht hast welche Informationen der Endpunkt aus deinem Salesforce System bekommt und welche Informationen du vom Endpunkt erhalten möchtest, legst du nun fest, wo die Informationen hergenommen werden, die an die Schnittstelle geschickt werden und wo die von der Schnittstelle erhaltenen Daten in deiner Salesforce Architektur gespeichert werden. Dies konfigurierst du mit einem sogenannten Mapping. Ein neues Mapping kannst du entweder innerhalb eines Endpunkts anlegen oder indem du im Reiter Mappings oben rechts auf “New” klickst.
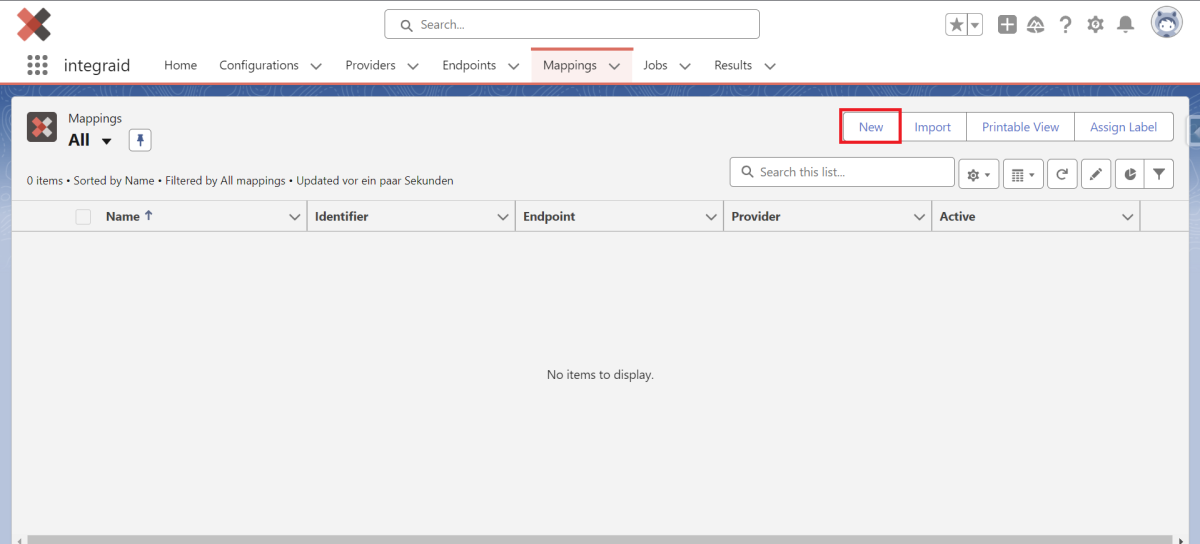 X
X
Eine Oberfläche zur Erstellung eines „Mapping“-Datensatzes öffnet sich. Gebe dem Mapping einen Namen und verknüpfe es mit einem Endpunkt. Nachdem du das Mapping gespeichert hast, kannst du nun mit der Konfiguration beginnen.
3.3.1. Scopes
Die Grundlage des Mappings bildet der Datenkontext, der durch sogenannte “Scopes” definiert wird. Scopes sind die Datenquellen oder "Datenwahrheiten", die für das Mapping verwendet werden. Sie können verschiedene Ebenen haben, wie z.B. Field Scopes, List Scopes und Free Scopes und erlauben den Zugriff auf die gesamte Datenstruktur in Salesforce.
Zuerst wird eine Primary Scope angelegt. Dies geschieht über den Button “Add Scope” oben rechts im Mapping-Datensatz. Sie definiert, unter welchem Objekt die für den Endpunkt relevante Information liegt.
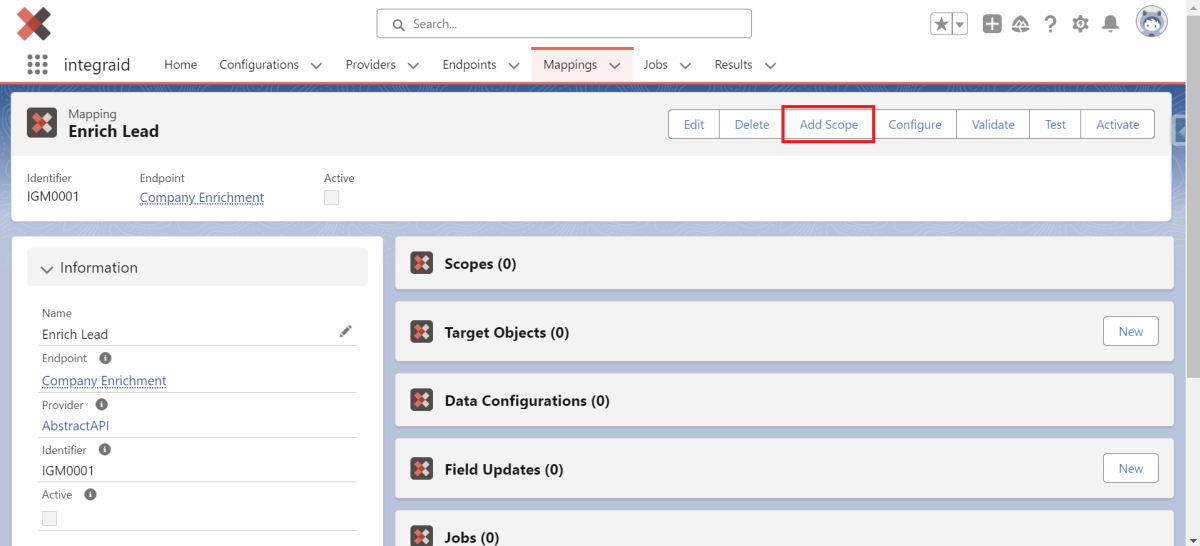 X
X
Hier wählst du dein gewünschtes Objekt aus. Wenn du z.B. Daten aus einem Account-Objekt für einen Callout benötigst, wählst du den Account als Primary Scope aus. Wir haben beispielsweise die Primary Scope als Lead definiert. Die Primary Scope wird im “Scope”- Datensatz sichtbar. Von der Primary Scope aus können nun weitere Scopes definiert werden. Dafür klickst du in den Scope Datensatz.
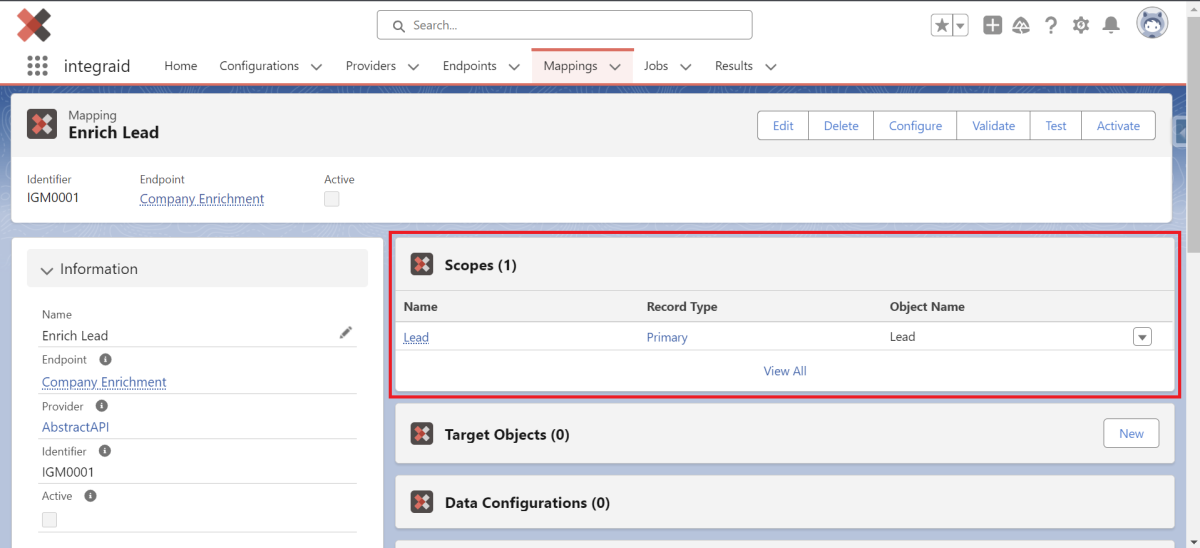 X
X
Zusätzlich zu der Primary Scope kannst du hier per Klick auf den Button “Create Child Scope” innerhalb der Primary Scope sogenannte Field Scopes und List Scopes erstellen. Diese sind sogenannte “Children” der Primary Scope, d.h. dass sie sich auf Daten innerhalb des Objektes der Primary Scope beziehen. Per Klick auf den Button “New” im Scope Datensatz kannst du außerdem eine Free Scope erstellen.
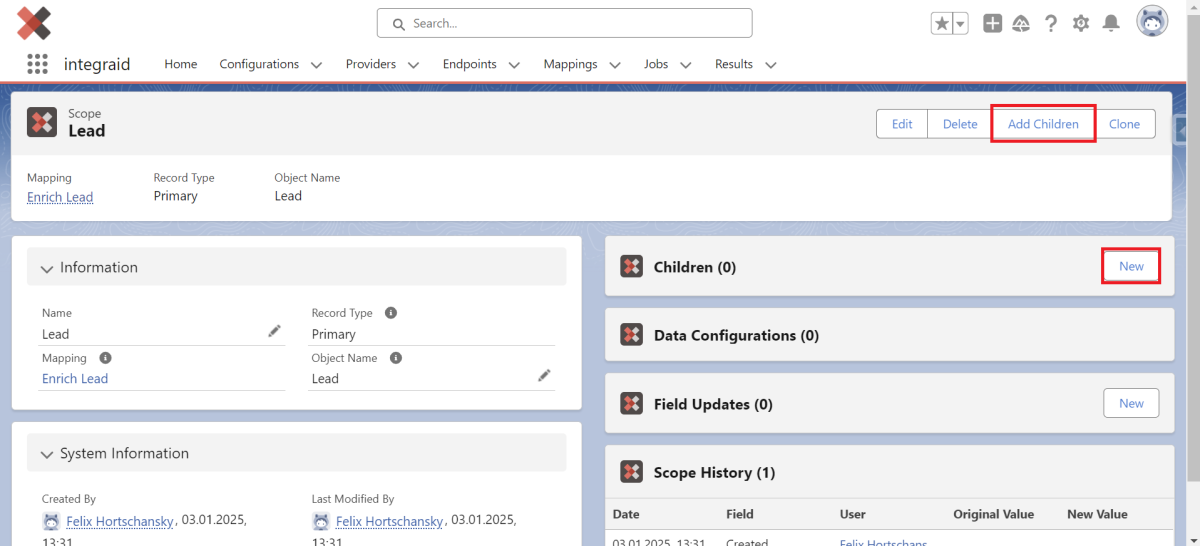 X
X
- Field Scopes beziehen sich auf Lookup Felder des Objektes und die Daten der Objekte, auf die das Lookup zeigt (Bsp. Ein Account).
- List Scopes beziehen sich auf Daten aus den Listen des Objekts (Bsp. Alle Kontakte unterhalb des im Field Scope definierten Accounts).
- Free Scopes beziehen sich auf alle Datensätze in Salesforce und müssen keine Verbindung zu einer Field- oder List Scope haben (Bsp. Alle Produkte in Salesforce).
Das Prinzip der Scopes kann am Anfang verwirrend sein, weshalb wir es später noch einmal anhand eines Beispiels erklären.
Record Rules
Falls du List Scopes definiert hast, werden alle Einträge der Liste in die Scope automatisch mitaufgenommen. Dies ist allerdings nicht in allen Fällen wünschenswert, oft benötigt man beispielsweise nur einige wenige oder bestimmte Einträge dieser Liste. Um solche Einschränkungen umzusetzen, lassen sich "Record Rules" definieren. Eine Record Rule kann eine von drei Operationen auf deiner List Scope ausführen, um sie nach deiner Vorstellung einzuschränken:
- Filter: Durch eine Filter Record Rule kannst du Einträge basierend auf einem Feld und dessen Zustand durch die Definition einer Bedingung filtern.
- Order: Order Record Rules sortieren die Liste basierend auf Feldern der Einträge. Du kannst mehrere Order Record Rules erstellen, für welche du dann über "Priority" eine Reihenfolge definieren kannst.
- Limit: Mit einer Limit Record Rule kannst du die Anzahl an Einträgen, welche in Betracht gezogen werden sollen, limitieren. Die Limit Record Rule wird immer nach allen anderen Record Rules angewendet.
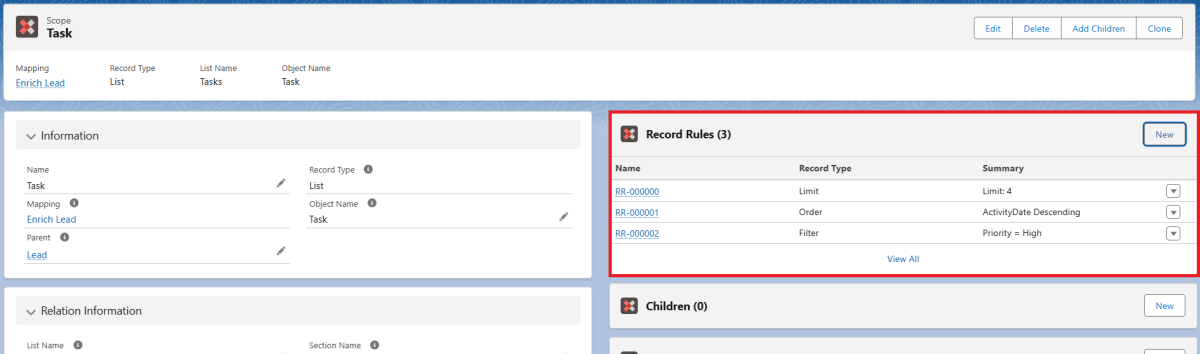 X
X
In diesem Beispiel haben wir die List Scope "Task" unter unserer Primary Scope "Lead" hinzugefügt. Da wir nicht alle Tasks miteinbeziehen möchten, haben wir einige Record Rules definiert. Die drei von uns definierten Regeln reduzieren die Einträge der List Scope nun auf die vier neuesten Tasks, deren Priorität auf 'High' gesetzt ist.
Hinweis: In einer Free Scope können auch Record Rules definiert werden, da eine Free Scope auch eine Liste sein kann.
3.3.2. Target Objects
Eingehend können zusätzlich zu den Scopes Target Objects angelegt werden. Diese sind speziell für Inbound-Mappings konzipiert und dienen dazu, spezifische Aktionen auf Salesforce-Objekten durchzuführen. Um ein neues Target Object zu erstellen, klicke auf den Button “New” neben “Target Objects”.
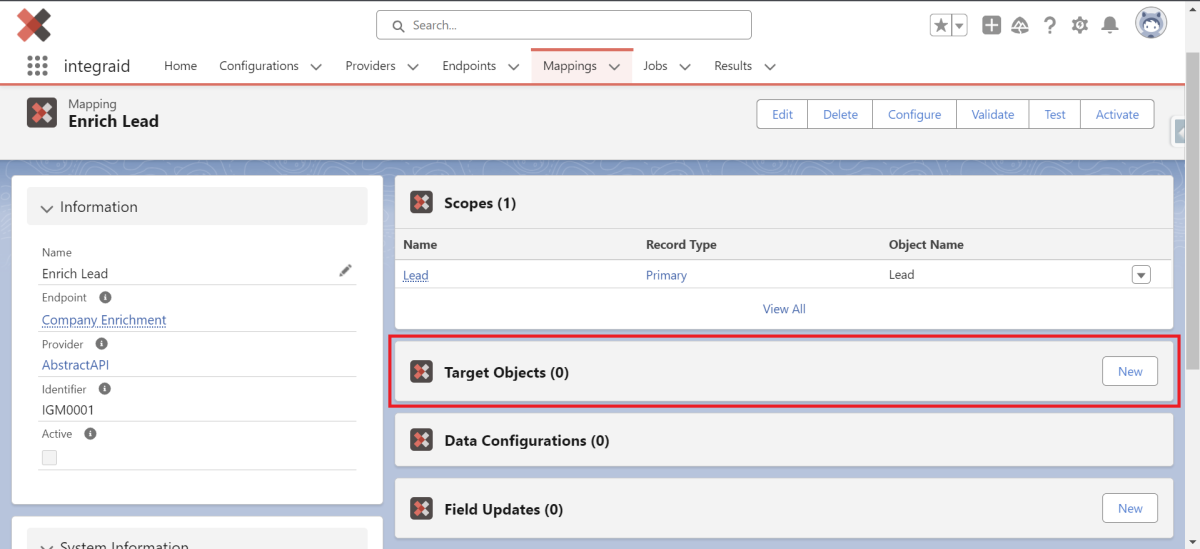 X
X
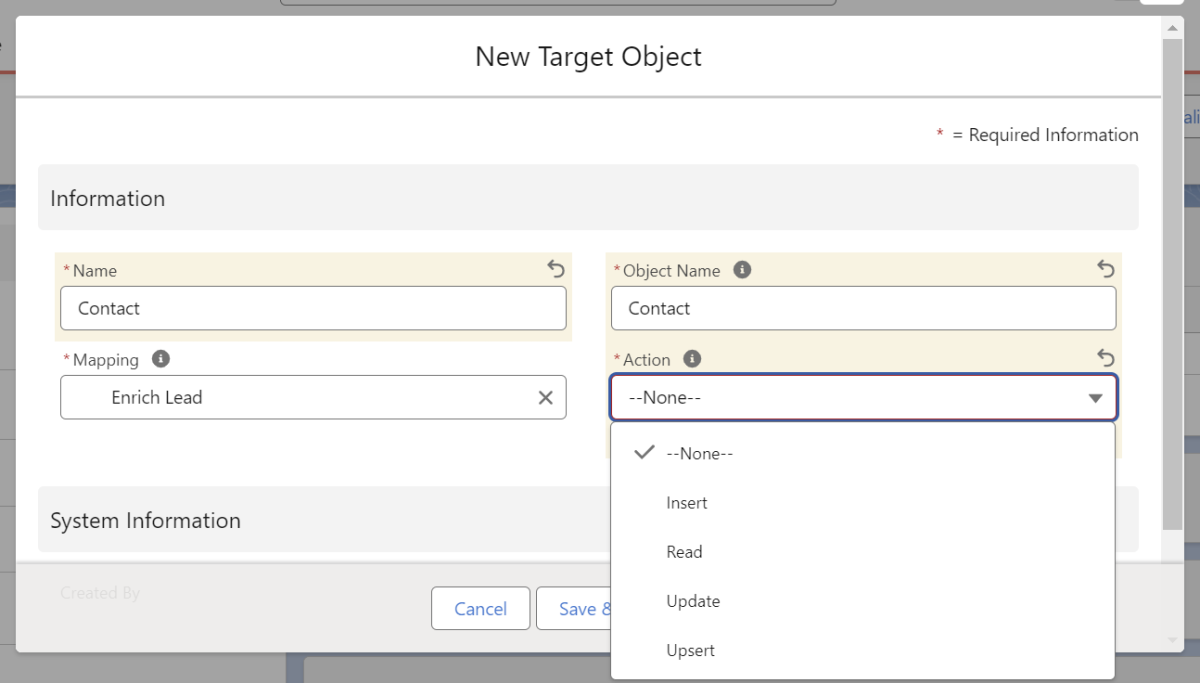
Eine Oberfläche zur Erstellung eines „Target Object“-Datensatzes öffnet sich. Gebe dem Target Object einen Namen, trage den Objektnamen ein und wähle eine Aktion.
 X
X
Folgende Aktionen stehen zur Auswahl:
- Insert: Hierbei werden neue Datensätze erstellt.
- Read: Die Daten werden lediglich gelesen, es werden aber keine Änderungen an Datensätzen vorgenommen.
- Update: Hierbei werden bestehende Datensätze aktualisiert.
- Upsert: Hierbei werden neue Datensätze eingefügt oder bestehende aktualisiert, falls ein passender Datensatz bereits existiert.
Hinweis: In diesem Bereich erfolgt nur die Definition aller Target Objects, auf welchen Operationen ausgeführt werden sollen. Die Konfiguration der Operationen erfolgt, wie auch bei Scopes, über den "Configure" Button.
3.3.3. Outbound Mapping
Nachdem du deine Scopes erstellt hast, geht es an die Konfiguration des Mappings. Über das Outbound Mapping legst du fest, wo die Informationen hergenommen werden, die an die Schnittstelle geschickt werden. Die Konfiguration startest du über den “Configure” Button innerhalb des Mapping-Datensatzes.
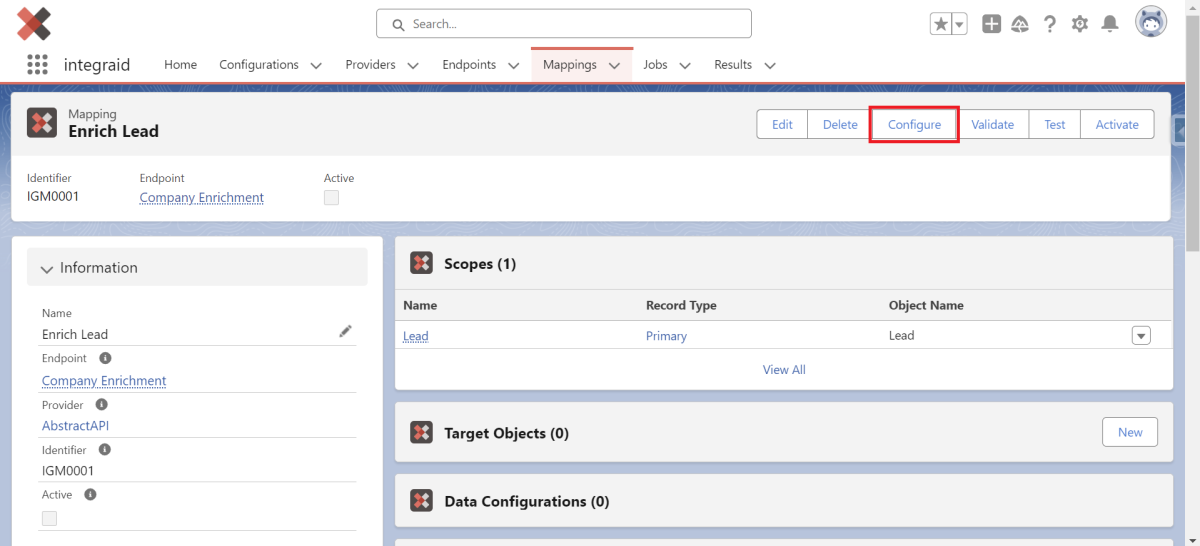 X
X
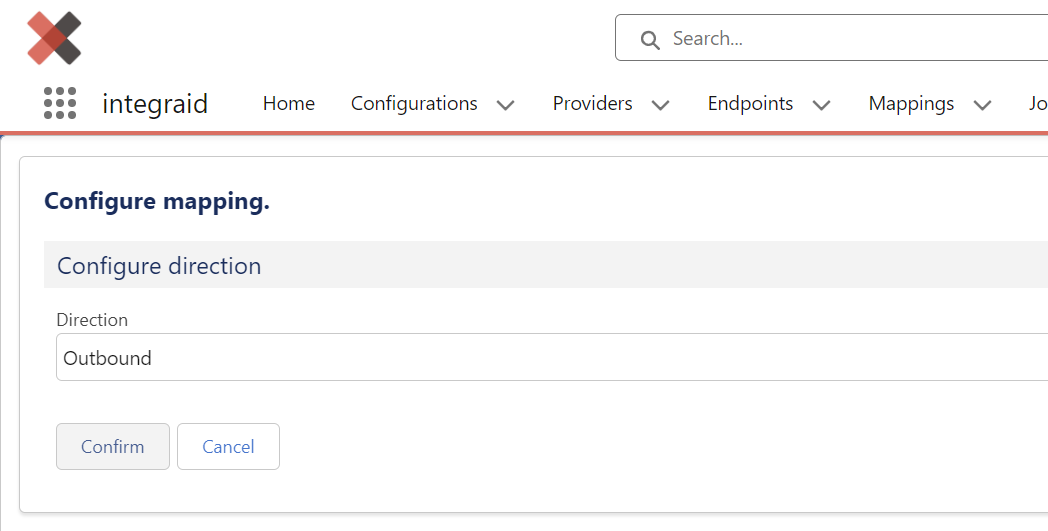
Als Richtung wählst du hierbei “Outbound” aus.
 X
X
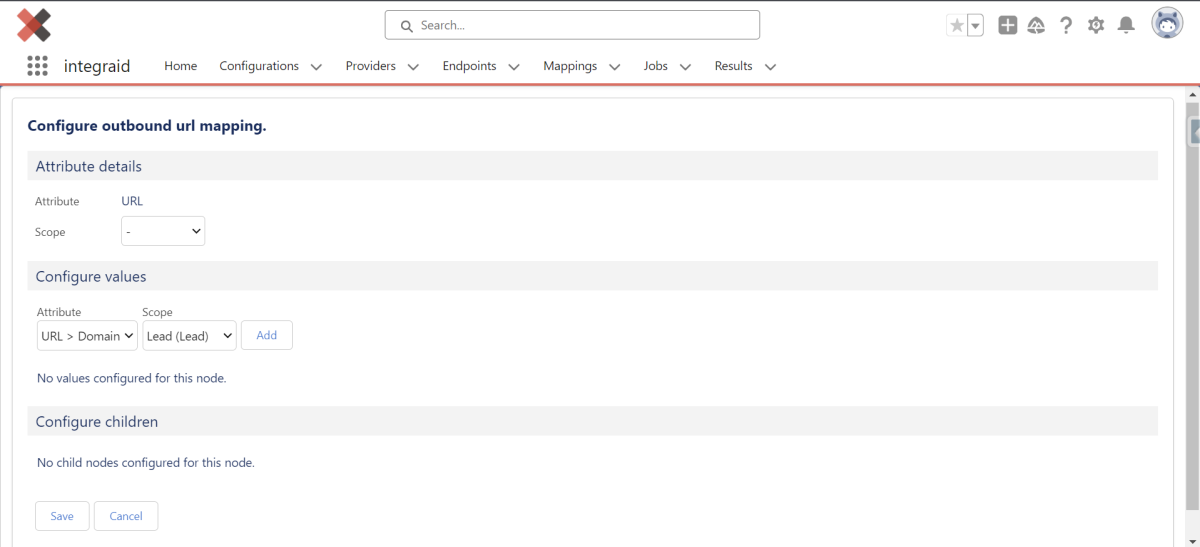
Es wurde bereits der Datenort ausgewählt, der im Endpunkt für Outbound festgelegt wurde.
 X
X
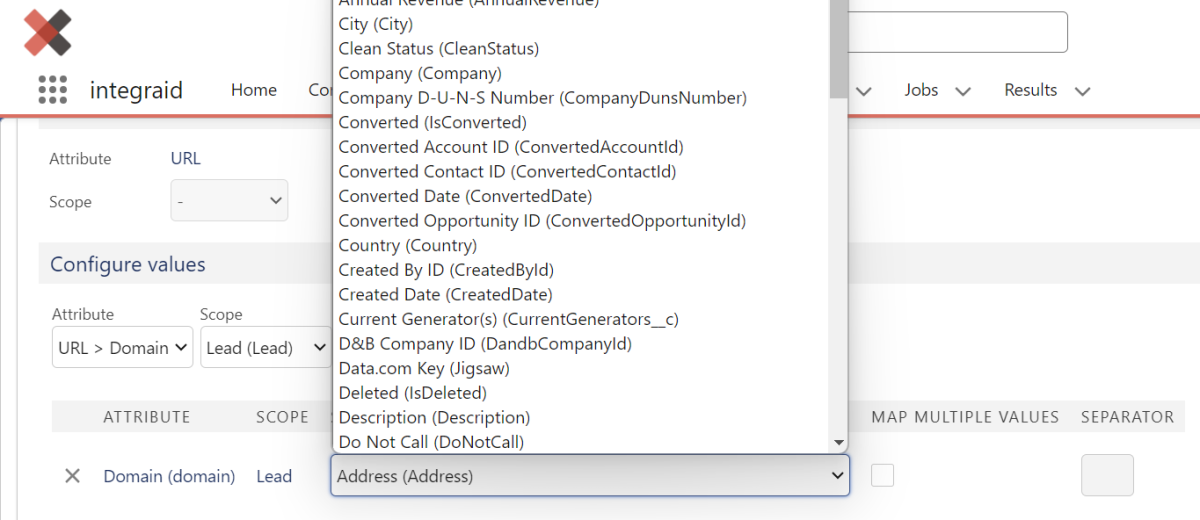
Nun wählst du deine Scope aus, welche die relevante Information beinhaltet. Per klick auf den Button “Add” fügst du das Attribut hinzu. Bei “Source” kannst du nun auf alle relevanten Felder zugreifen, die die ausgehende Information beinhalten.
 X
X
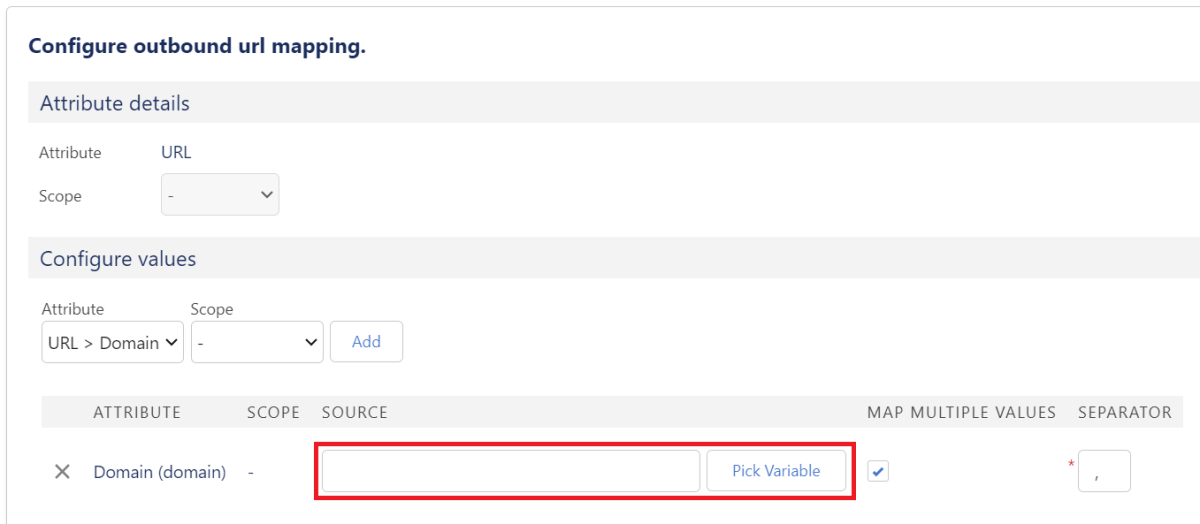
Für das Handling von Arrays gibt es zusätzlich die Checkbox “Map Multiple Values”, wobei die Werte durch ein im Feld “Seperator” angegebenes Zeichen getrennt werden.
Du hast jedoch ebenfalls die Option, das Attribut statisch zu befüllen, indem du das Feld “Scope” weglässt. Bei “Source” kannst du dann deinen Wert eingeben.
 X
X
Per Klick auf den Button “Pick Variable” hast du außerdem die Möglichkeit, auf bestimmte Variablen zuzugreifen, die häufig dynamisch verwendet werden.
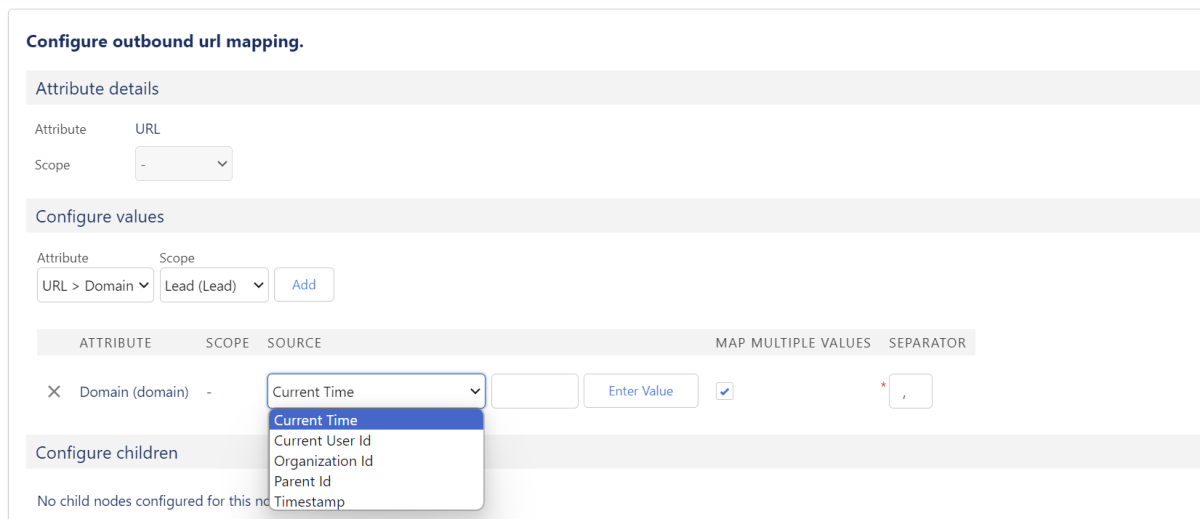 X
X
Sie können genutzt werden, um dynamische Werte zu generieren, die später in dem Feld daneben auch angepasst werden können (z.B. Timestamp minus eine Woche). Es ist möglich, eine Abweichung in Minuten einzutragen, um dynamische Datums- und Zeitwerte zu definieren.
3.3.4. Inbound Mapping
Über das Inbound Mapping legst du fest, wo die von der Schnittstelle erhaltenen Daten in deiner Salesforce Architektur gespeichert werden sollen. Die Konfiguration startest du ebenfalls über den “Configure” Button innerhalb des Mapping-Datensatzes, wählst als Richtung diesmal jedoch “Inbound” aus.
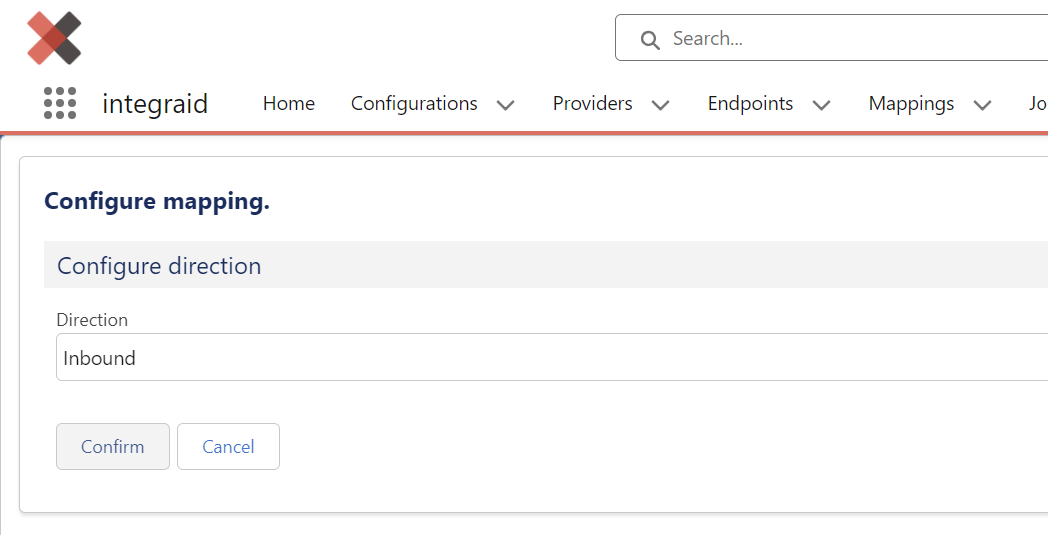 X
X
Hier wählst du nun bei “Target” dein Zielobjekt aus, auf welches die von der Schnittstelle erhaltenen Werte übertragen werden sollen. Bei “Attribute” hast du Zugriff auf alle Attribute, die im Endpunkt festgelegt wurden.
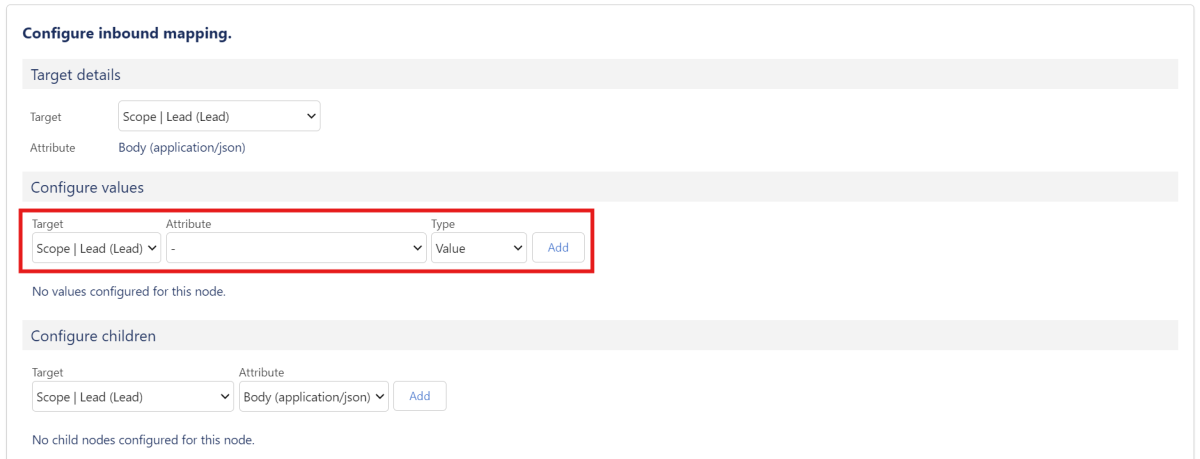 X
X
Per Klick auf den Button “Add” kannst du die Konfiguration hinzufügen und im nächsten Schritt bei “Field” das Feld auswählen, auf welchem das jeweilige Attribut abgebildet werden soll.
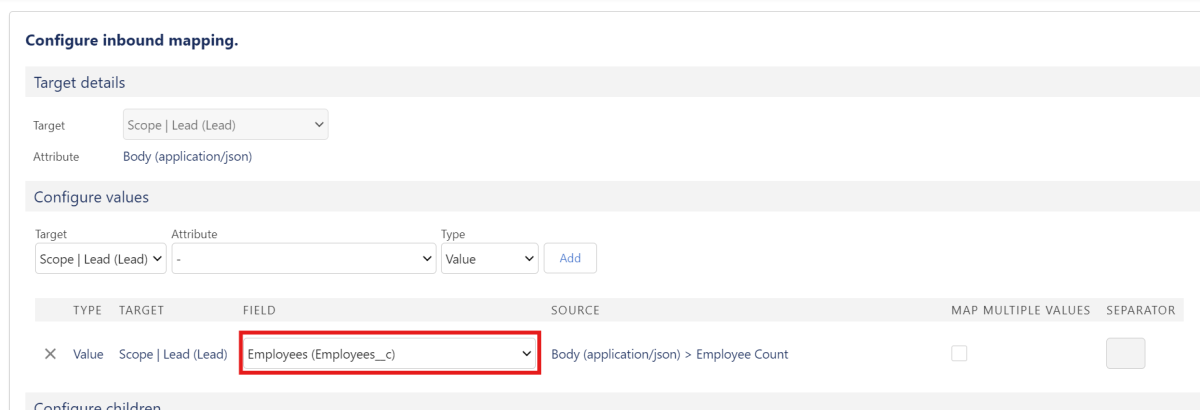 X
X
Auch hier ermöglicht die Checkbox "Map multiple values" die Verarbeitung von Arrays oder kommaseparierten Werten. Wenn ein Attribut mehrere Werte enthält, kann also mit der Checkbox gesteuert werden, wie diese Werte in Salesforce geschrieben werden (z.B. alle Werte kommasepariert in ein Textfeld oder in eine Mehrfachauswahlliste).
Wird kein Attribut angegeben, hast du auch hier die Möglichkeit, statische Werte anzugeben oder auf die Variablen “Response Code” und “Timestamp” zuzugreifen.
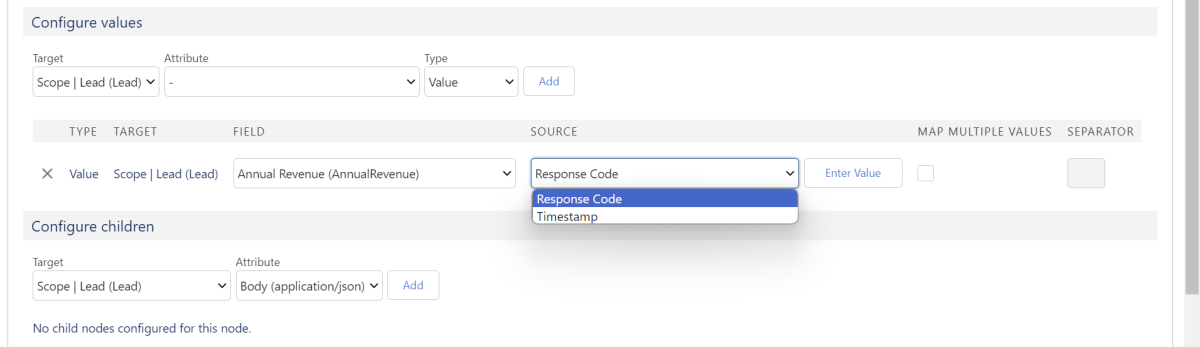 X
X
Im Abschnitt “Configure Children” kannst du Datensätze in Bezug auf ein Parent Object erstellen. Als “Target” legst du hier dein vorher angelegtes Target Object fest und klickst auf “Add”.
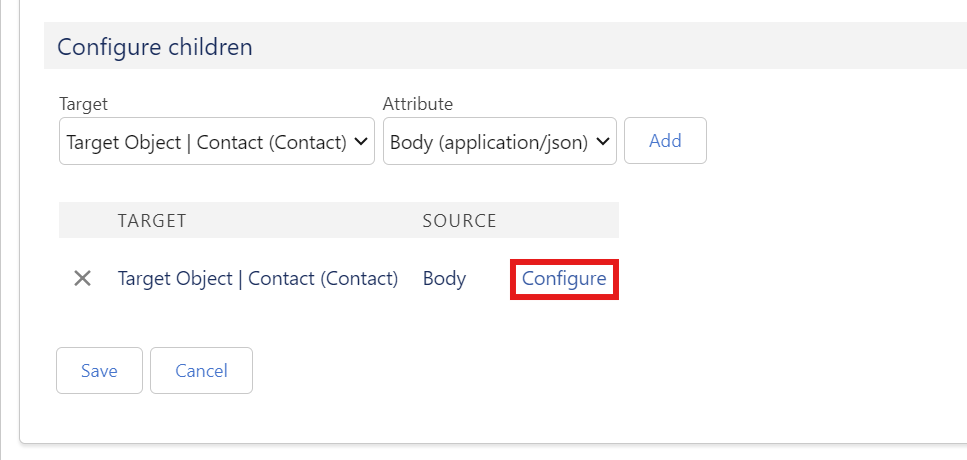 X
X
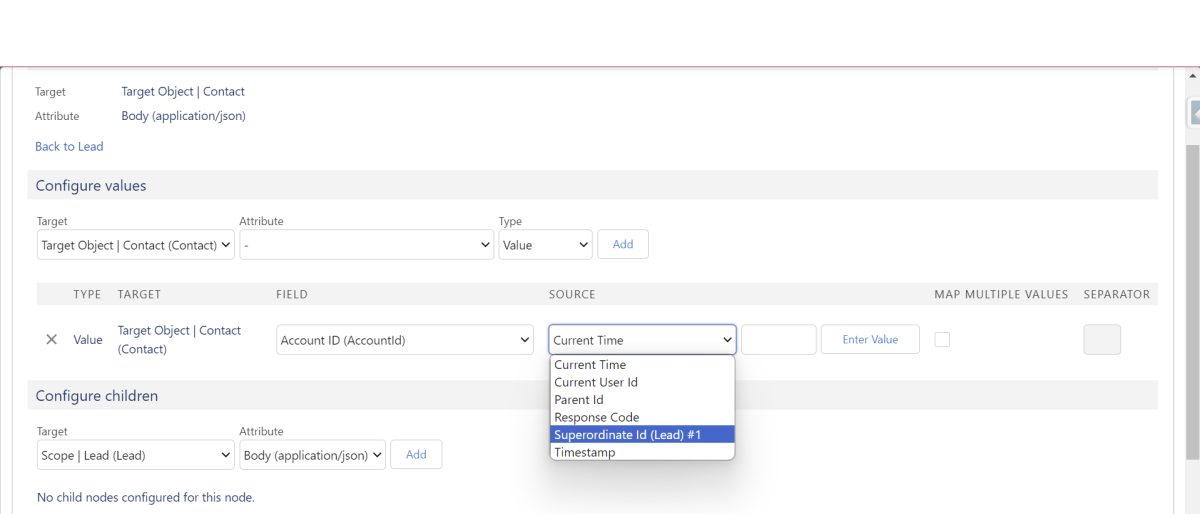
Nun kannst du auf “Configure” klicken und gehst in der Konfiguration eine Ebene tiefer. Hier funktioniert die Konfiguration genau wie auf Ebene des Parent Objects. Lässt du das Feld 'Attribute' frei, kannst du einerseits freien Text definieren, und hast andererseits Zugriff auf eine Liste vordefinierter Variablen.
 X
X
Für die zeitbasierten Variablen (Current Time, Timestamp) kannst du zudem ein Offset definieren. Dieser kann in das leere Feld neben der Variable eingetragen werden und wird in Minuten berechnet. Eine Eingabe von „+60” in das leere Feld fügt beispielsweise 60 Minuten zur zeitbasierten Variablen hinzu, während eine Eingabe von „-60” 60 Minuten abzieht.
Durch die Variable 'Superordinate Id' hast du Zugriff auf alle IDs der Parent Objects. So ist es möglich, auf Objekte zuzugreifen, die mehrere Ebenen über deiner Position liegen. Die Nummerierung bezieht sich dabei auf deine aktuelle Position (#1=eine Position über dir, #2=zwei Positionen über dir).
Mit dem Button “Back to Parent Object” kommst du wieder auf die höhere Ebene.
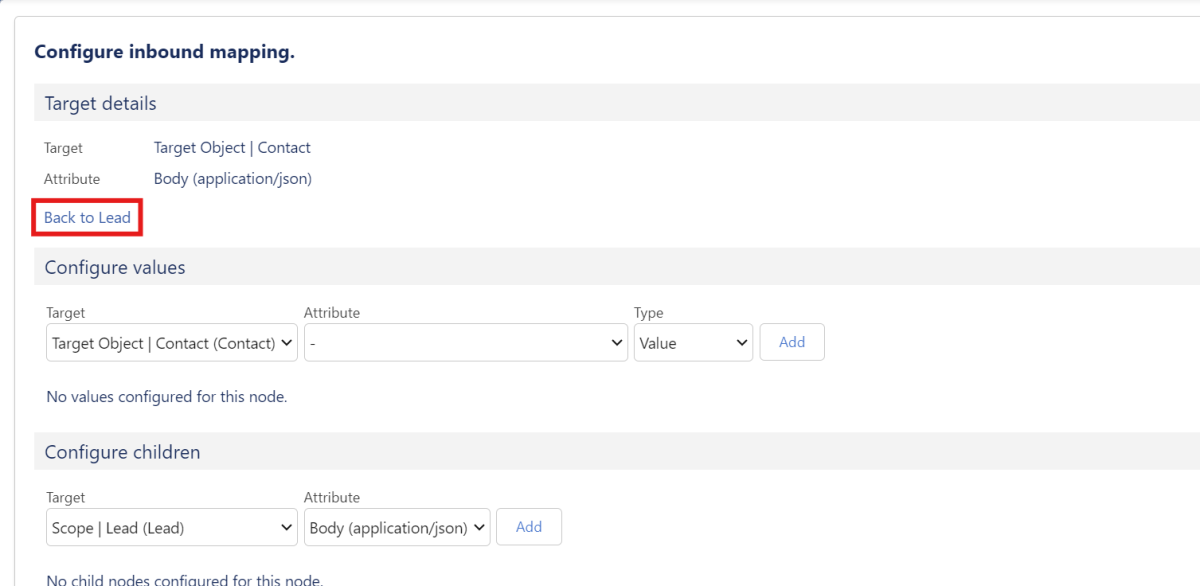 X
X
Hinweis: Du kannst sowohl Merge-Felder* als auch Merge-Attribute* verwenden, um Daten aus dem Parent Object oder der Antwort der Schnittstelle zu referenzieren und in die Felder des Child Objekts zu schreiben. Das System validiert automatisch, ob die Merge-Felder korrekt eingegeben wurden.
3.3.5. Merge-Attribute
Merge-Attribute können auf gleiche Weise wie Merge-Felder verwendet werden, mit dem Unterschied, dass Merge-Attribute zur Referenzierung eines Werts der eingehenden oder ausgehenden Daten, die von der Schnittstelle gesendet werden, anstatt für Daten aus deiner Salesforce Organisation. Daher können Merge-Attribute auch nur an zwei Stellen genutzt werden:
1. Inbound Mapping eines Callouts
2. Outbound Mapping eines Callins
Um ein Merge-Attribut zu verwenden, füge einen neuen Eintrag in 'Configure values' mit deinem gewünschen Zielobjekt als 'Target' hinzu, und lasse das Feld 'Attribute' leer. Wähle außerdem 'Value' als 'Type'. Dadurch wird ein neuer Eintrag mit einem leeren Textfeld als Attribut erstellt, welches du sowohl mit Text als auch nun mit Merge-Attributen ausfüllen kannst.
Syntax für Merge-Attribute
Merge-Attribute müssen anders als Merge-Felder mit einem '$' gekennzeichnet werden. Die komplette Syntax für ein Merge-Attribut lautet dann:
{$Location.Node.Value}
wobei 'Location' den Ort der Daten (Body, Header, URL), 'Node' den Namen des Knoten, in welchem das Attribut liegt, und 'Value' den Namen des Attributs darstellt.
Attribute können je nach deiner definierten Struktur mehrere Knoten tief liegen. Um ein Attribut in komplexen Strukturen korrekt zu referenzieren, muss der komplette Pfad zum Attribut im Merge-Attribut angegeben werden. Wenn du beispielsweise ein Attribut "Street_Name" hast, welches in mehreren Knoten mit der Struktur Body > Company > Address > Street_Name verschachtelt liegt, dann muss das zugehörige Merge-Attribut {$Body.Company.Address.Street_Name} lauten.
Hinweis: Du kannst über Mergefelder auch auf die vordefinierten Variablen zugreifen. Dies geschieht ganz einfach über {variableName}. Den Offset für zeitbasierte Variablen kannst du über den anhang von ":+-Number" einfügen, sowie die Position der Superordinate ID über ":Number".
Beispiele: {responseCode}, {timestamp:+60}, {currentUserId}, {currentTime:-60}, {superordinateId:2}
Beispiel:
In diesem Beispiel erhalten wir eine Antwort einer Schnittstelle mit Informationen über ein Unternehmen und dessen Standort. Wir möchten nun den Inhalt des Attributs "Country" aus dem Antwort-Körper in das Feld "Country" unseres Leads schreiben, allerdings möchten wir dabei noch den Text "Country :" voranstellen. Um das umzusetzen, nutzen wir ein Merge-Attribut.
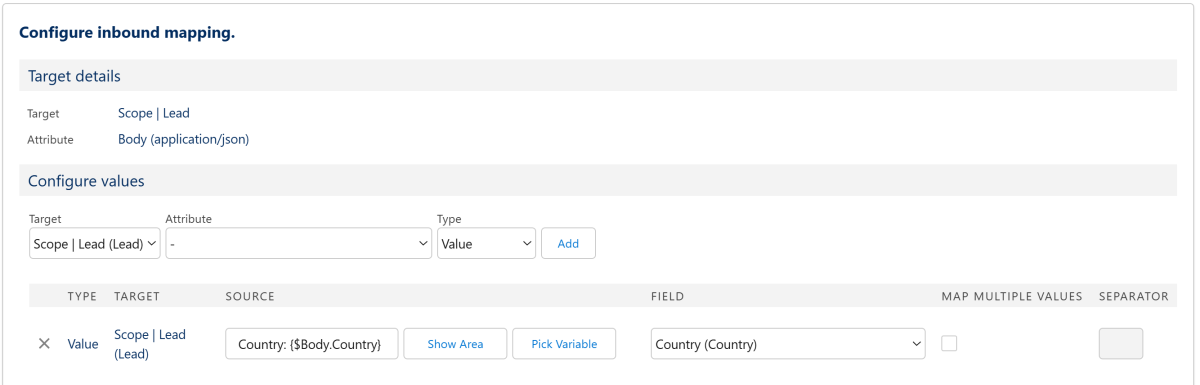 X
X
Mit dieser Konfiguration steht nach der Verarbeitung der Schnittstellen-Antwort, welches Informationen über eine deutsches Unternehmen beinhaltet, nun "Country: Deutschland" im "Country"-Feld unseres Leads.
Einbettung aller Elemente einer List Scope
Wird eine List Scope über ein normales Mergefield verwendet, wird nur der erste Eintrag dieser List Scope in Betracht gezogen. Möchte man alle Einträge der List Scope einbetten, muss eine andere Syntax verwendet werden. Diese lautet wie folgt:
Für Mergefelder: {tableStart:Scope} …content... {tableEnd:Scope}
Für Merge-Attribute: {$tableStart:Location.Node...} ....content.... {$tableEnd:Location.Node....}
Hier steht 'Scope' als Platzhalter für den API-Namen der List Scope. Für Merge-Attribute muss der vollständige Pfad zur gewünschten Knoten für tableStart und tableEnd, sowie das führende Zeichen '$' (was darauf hinweist, dass dieses Feld ein Merge-Attribut ist) angegeben werden.
Im Bereich content (also zwischen tableStart und tableEnd) kann Inhalt formuliert werden, welcher für jeden Eintrag der List Scope/des Knotens miteinbezogen wird. Hier sind Mergefelder/Merge-Attribute sowie HTML-formatierter Text möglich. Ein Beispiel für die Anwendung dieser Syntax lautet:
{tableStart:Tasks} - {Task.Description} <br> {tableEnd:Tasks} für Mergefelder ODER
{$tableStart:Body.Node} - {$Body.Node.Description} <br> {$tableEnd:Body.Node} für Merge-Attribute
Diese Operation schreibt die Beschreibungen aller Tasks aus unserer List Scope 'Tasks' (oder einer Gruppe von Knoten „Node“) in ein Feld. Das Kürzel <br> wird in HTML als Zeilenumbruch ausgewertet.
3.3.6. IF Statements
Um in einer Feldkonfiguration verschiedene Werte anhand von Bedingungen anzeigen zu lassen, kann mit IF-Bedingungen gearbeitet werden. Hier wird ein bestimmter Wert (z. B. aus einem Mergefeld/Mergeattribut) geprüft und ein Ergebnis angezeigt, wenn der Wert eine Bedingung erfüllt. Wird die Bedingung nicht erfüllt kann ein anderer Wert angezeigt werden. Somit können anhand von Daten der Schnittstellenantwort sowie aus Salesforce verschiedene Werte in deinem Salesforce System gespeichert werden.
Die Syntax für IF-Bedingungen lautet:
IF( Feldname/Mergeattribut == "Wert", "WertWennBedingungZutrifft", "WertWennBedingungNICHTZutrifft" )
Dabei wird zuerst die Bedindung definiert, und danach kommasepariert der Wert, falls die Bedingung erfüllt ist und der Wert, falls die Bedingung nicht erfüllt ist. Für erweiterte Bedinungen können die Werte selbst wieder IF Bedingungen enthalten.
Für die Bedindung können folgende Operatoren verwendet werden:
- == (erfüllt, falls die Werte gleich sind)
- != (erfüllt, falls die Werte ungleich sind)
- <, > (erfüllt, falls der Wert echt kleiner/größer ist)
- <=, >= (erfüllt, falls der Wert kleiner gleich/größer gleich ist)
Mit diesen Operatoren können sowohl numerische Werte als auch Datum und Zeitpunkte vergleichen
Für textuelle Verleiche gibt es außerdem folgende Operatoren:
- contains (erfüllt, falls das Feld den Bedingungstext enthält)
- not contains (erfüllt, falls das Feld den Bedingungstext nicht enthält)
Hinweis: Währungsfelder (Felder vom Typ "Currency") können nicht als numerische Werte verglichen werden. Willst du trotzdem den Wert eines Währungsfeldes im Vergleich nutzen, erstelle ein Formelfeld, welches den Wert des Währungsfeldes als "Number" speichert.
3.3.7. Field Updates
Field Updates sind in integraid eine Funktion, die es ermöglicht, Felder in Salesforce zu aktualisieren, nachdem ein Callout oder ein Callin stattgefunden hat. Im Gegensatz zu Data Configurations, die abhängig von der Antwort der Schnittstelle aktualisiert werden, werden Field Updates immer ausgeführt, unabhängig davon, ob die Schnittstelle erfolgreich war, einen Fehler zurückgegeben hat oder gar keine Antwort gegeben hat. Ein neues Field Update kannst du erstellen, indem du auf den Button “New” neben Field Updates innerhalb deines Mapping-Datensatzes klickst.
 X
X
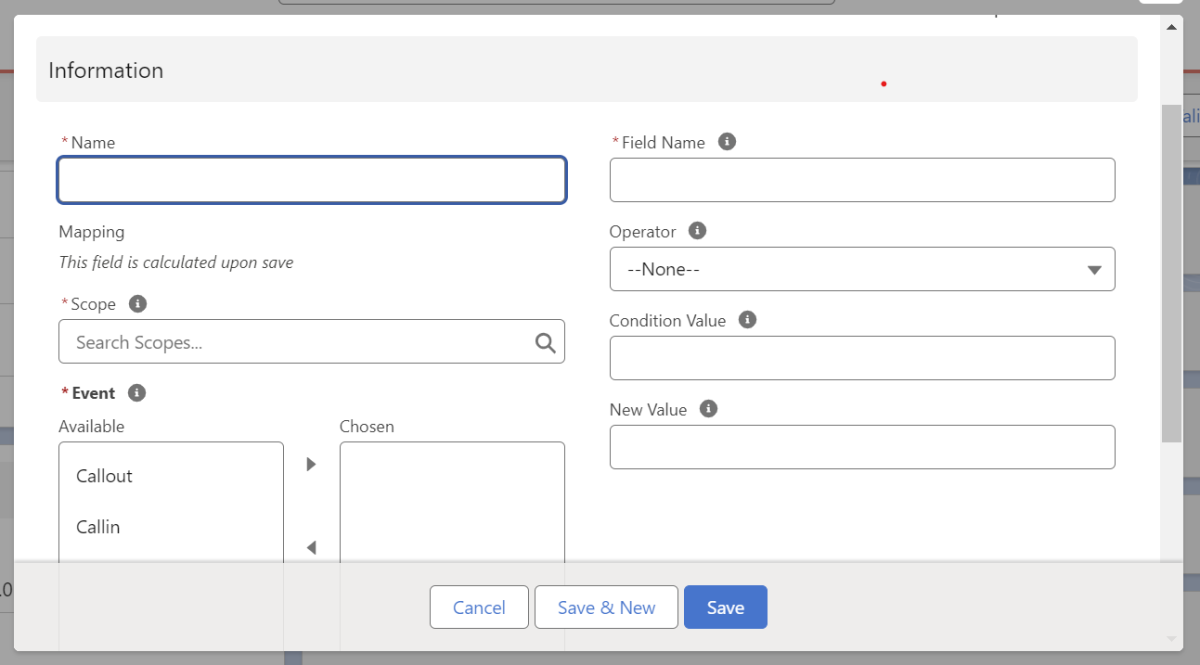
Eine Oberfläche zur Erstellung eines „Field-Update“-Datensatzes öffnet sich.
 X
X
Hier kannst du dem Record einen Namen geben, die Scope festlegen und bei “Field Name” den Namen des Feldes angeben, welches aktualisiert werden soll. Bei “Operator” kannst du den Vergleichsoperator angeben, der abgeglichen werden soll, bei “Condition Value” den aktuellen Wert des Zielfelds und bei “New Value” den Zielwert für das aktualisierte Feld. Der Wert in “New Value” wird hier also nur geschrieben, wenn die in “Operator” angegebene Bedingung zutrifft (z.B. ein Feld nur dann beschreiben, wenn es davor leer ist). Zudem wählst du bei “Event” die Ereignisse aus, welche das Field Update auslösen sollen.
Wenn das Mapping fertig Konfiguriert ist, kannst du es per Klick auf den Button “Validate” validieren und per Klick auf den Button “Activate” aktivieren. Um es zu testen, kannst du auf den Button “Test” klicken.
 X
X
Hier kannst du einen Record innerhalb deiner Scopes auswählen und auf “Create” klicken, um einen Job zu erstellen.
 X
X
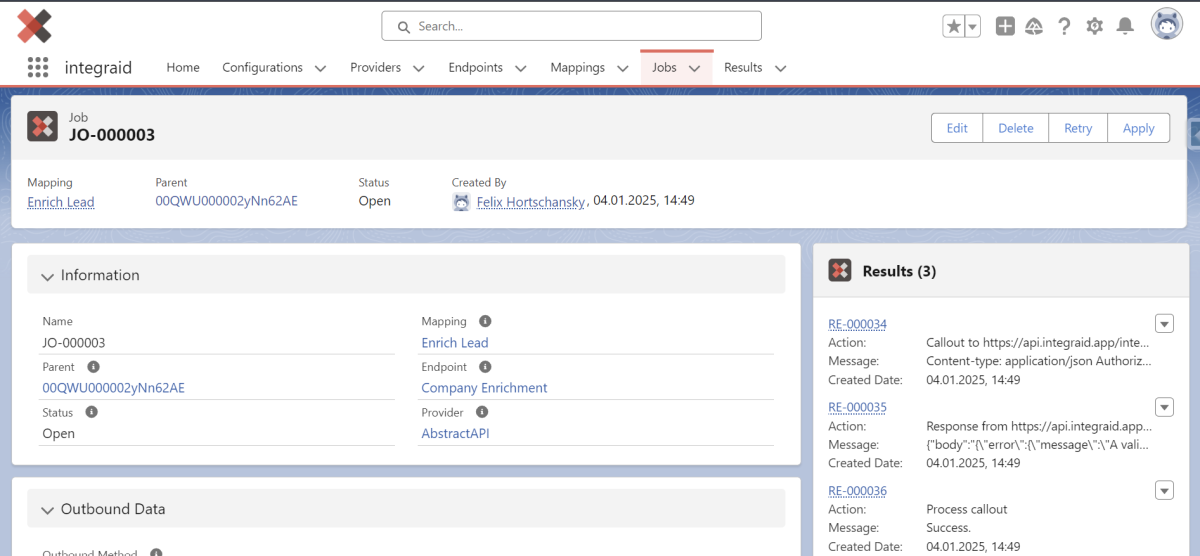
3.3.8. Jobs
Jobs sind in integraid eine zentrale Komponente, die jeden Callout und jeden Callin handhabt. Sie dienen als eine Art Protokoll oder Aufzeichnung für jede Interaktion mit einer Schnittstelle und ermöglichen die asynchrone Verarbeitung von Daten. Alle deine Jobs findest du im gleichnamigen Reiter auf der integraid Oberfläche.
 X
X
- Wenn ein Test-Job aus einem Mapping heraus erstellt wird, wird der Callout ausgeführt, aber es werden keine Daten in die Datenbank geschrieben. Dies verhindert, dass Live-Daten durch Testläufe beeinflusst werden.
- Wenn ein Fehler bei der Datenanwendung auftritt, kann der zugrunde liegende Fehler behoben und die Datenanwendung über den Button "Retry" im Job wiederholt werden.
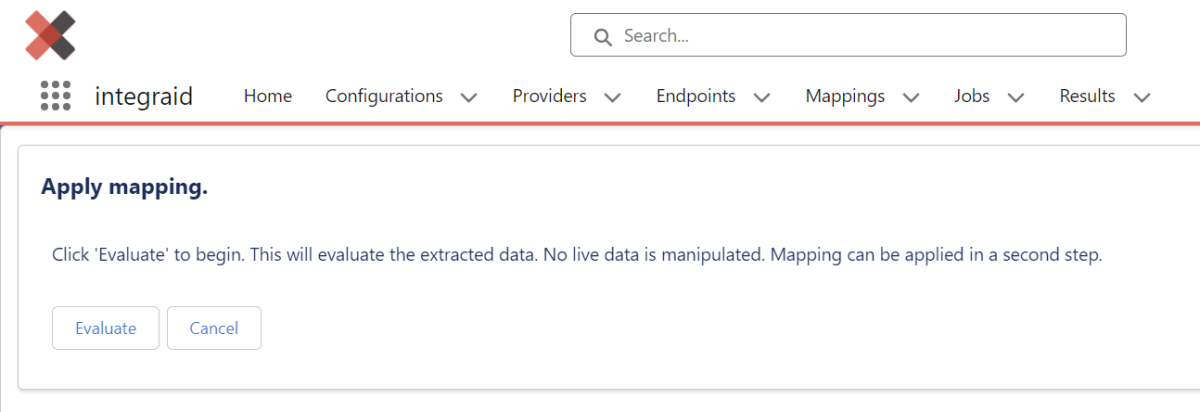
- Der Button "Apply" dient dazu, die Anwendung eines Jobs manuell anzustoßen. Das bedeutet, dass die Ergebnisse eines Callouts in die Datenbank geschrieben werden. Es gibt anschließend eine "Evaluate" Option, mit der man sich die Auswirkung der Anwendung anzeigen lassen kann, bevor die Anwendung ausgeführt wird.
 X
X
Jeder Job hat außerdem einen Status, der anzeigt, ob der Job noch offen ist oder erfolgreich abgeschlossen wurde. Bei einem Fehler bleibt der Job offen, was es dir ermöglicht, auf die offenen Jobs zu reagieren und diese gegebenenfalls neu auszuführen.
3.4. Beispiel Abstract API
In diesem Abschnitt zeigen wir dir die Funktionsweise von integraid anhand des Beispiels der Company Enrichment API. Hierbei wollen wir anhand der angegebenen Website eines Leads Informationen über das Unternehmen erhalten und automatisch in unser Salesforce System extrahieren. Die Informationen nehmen wir aus der Schnittstellendokumentation: https://docs.abstractapi.com/company-enrichment
3.4.1. Vorbereitung in Salesforce
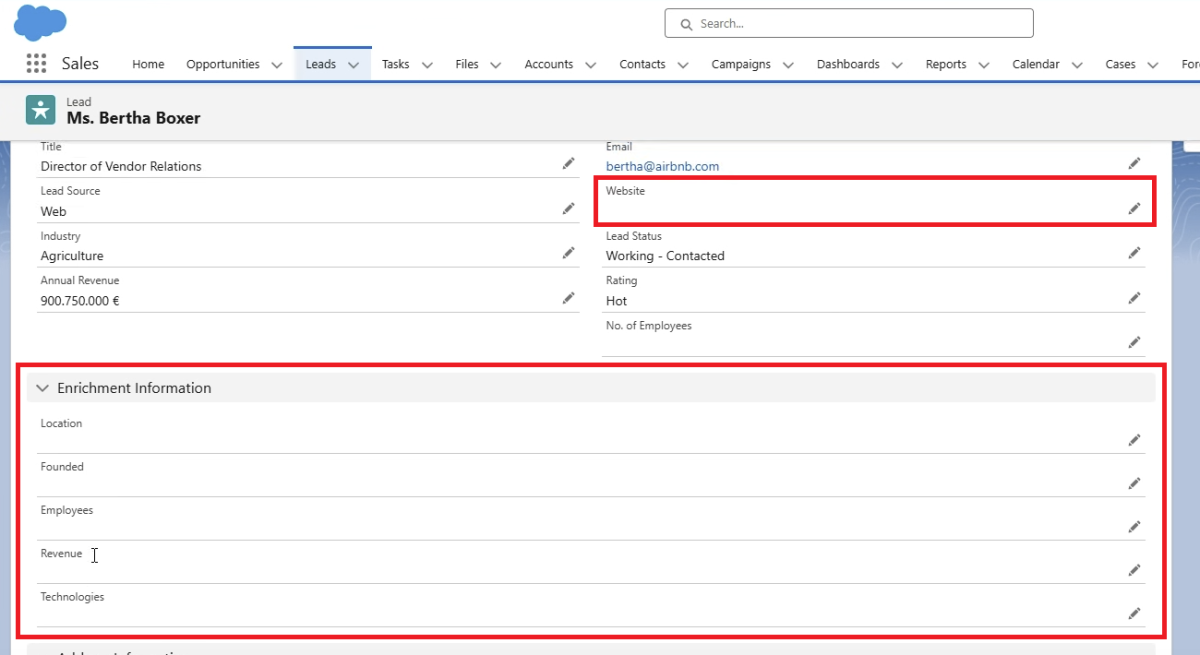
- Felder anlegen: Im Standard Leadobjekt von Salesforce legen wir zuerst fünf Felder an, um die von Abstract API zurückgelieferten Daten zu speichern. Diese Felder sind:
- Location (Ort)
- Founded (Gründungsjahr)
- Employees (Anzahl der Mitarbeiter)
- Revenue (Jahresumsatz)
- Technologies (Liste der eingesetzten Technologien)
- Formelfeld anlegen: Wir legen zudem ein Formelfeld an, das aus dem Webseitenfeld die Domain extrahiert. Abstract API benötigt die Domain als Erkennungsmerkmal für die Firma.
 X
X
3.4.2. Konfiguration in integraid
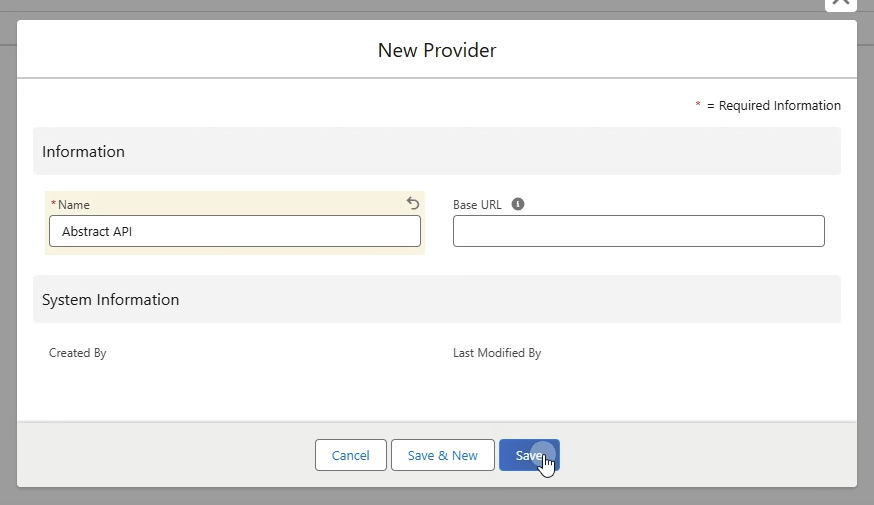
- Provider anlegen:
- Als erstes legen wir einen neuen Provider Datensatz in integraid an, der den Schnittstellenanbieter definiert. In diesem Fall nennen wir ihn "Abstract API". Die Base URL lassen wir leer.
 X
X
- Autorisierung konfigurieren: Als zweiten Schritt konfigurieren wir die Autorisierung. Den Typ der Autorisierung setzen wir auf "URL" und den API-Schlüssel von Abstract API übergeben wir als URL-Parameter mit dem Namen "api_key".
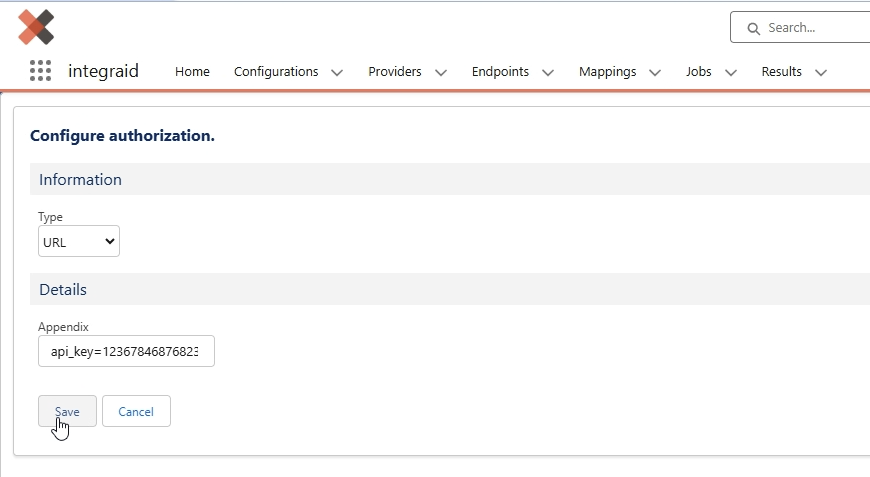 X
X
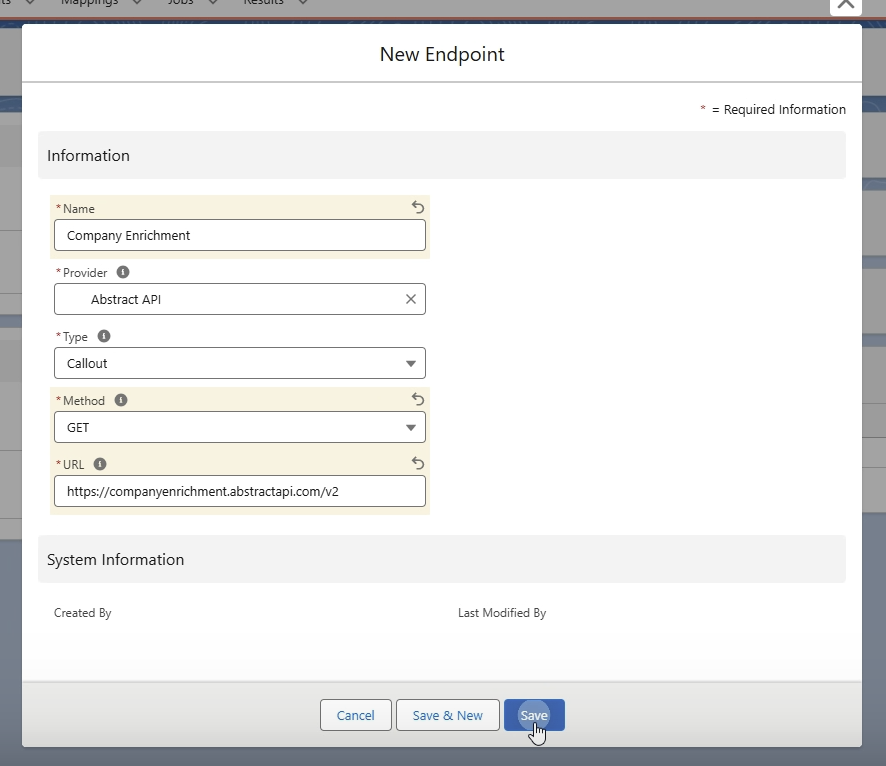
- Endpunkt definieren: Der dritte Schritt ist die Konfiguration des Endpunkts. Dieser beinhaltet die Art der Daten, die die Schnittstelle erwartet, und die Struktur der zurückgegebenen Daten. Wir legen einen Endpunkt mit folgenden Informationen an:
- Name: Company Enrichment
- Provider: Abstract API
- Type: Callout
- Method: GET
- URL: https://companyenrichment.abstractapi.com/v2
Die HTTP-Methode (GET) und die URL der Abstract API haben wir aus der Schnittstellendokumentation kopiert.
 X
X
Outbound konfigurieren: In der Schnittstellendoku können wir sehen, dass die Schnittstelle einen URL-Parameter namens "Domain" erwartet.
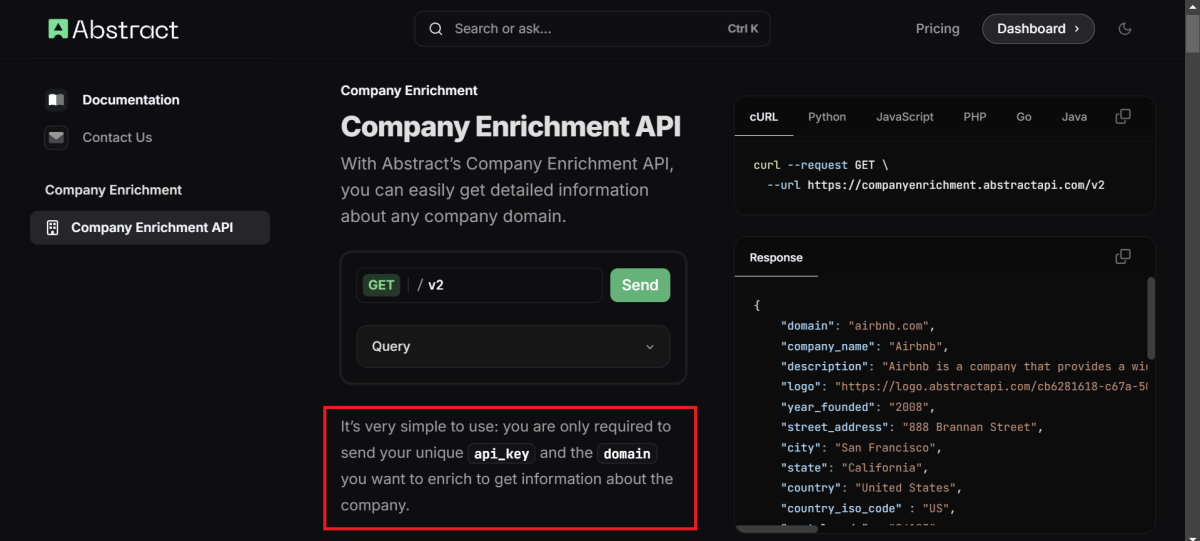 X
X
Wir klicken also auf den “Configure”-Button innerhalb des Endpunkts, wählen “Outbound” und anschließend “URL”. In den Identifier tragen wir “domain” ein und wählen “Value” als Type.
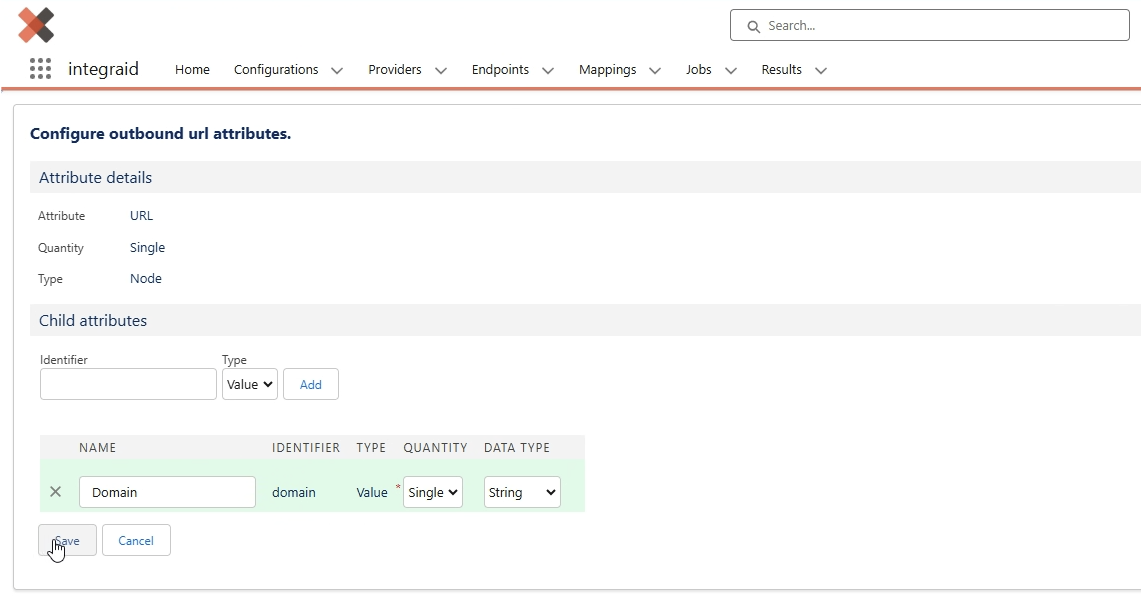 X
X
Inbound konfigurieren: Hier wird die Struktur der Antwort von Abstract API definiert. In der Schnittstellendokumentation sehen wir eine Beispielantwort im JSON-Format, welche wir kopieren und in integraid importieren können.
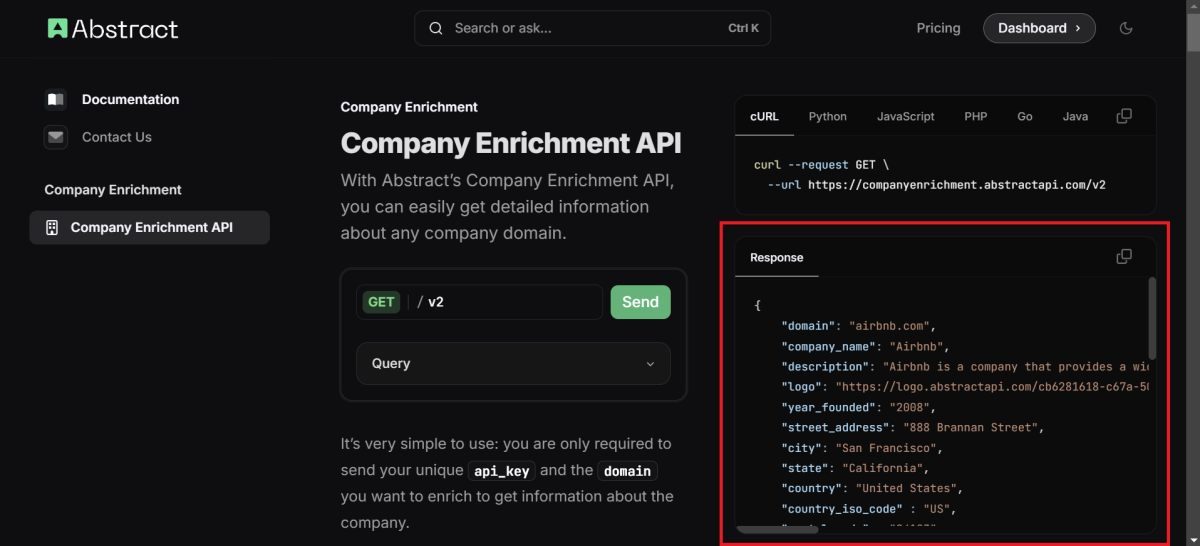 X
X
Wir klicken erneut auf den “Configure”-Button innerhalb des Endpunkts, wählen “Inbound” und anschließend “Body”. Den Content Type setzen wir auf "Application JSON" und bei Type wählen wir “Node”. Nun klicken wir auf “Import” und kopieren anschließend unsere Beispielantwort in das Feld “Input”. Per Klick auf den Button “Import” wird nun die Attribut-Struktur automatisch angelegt.
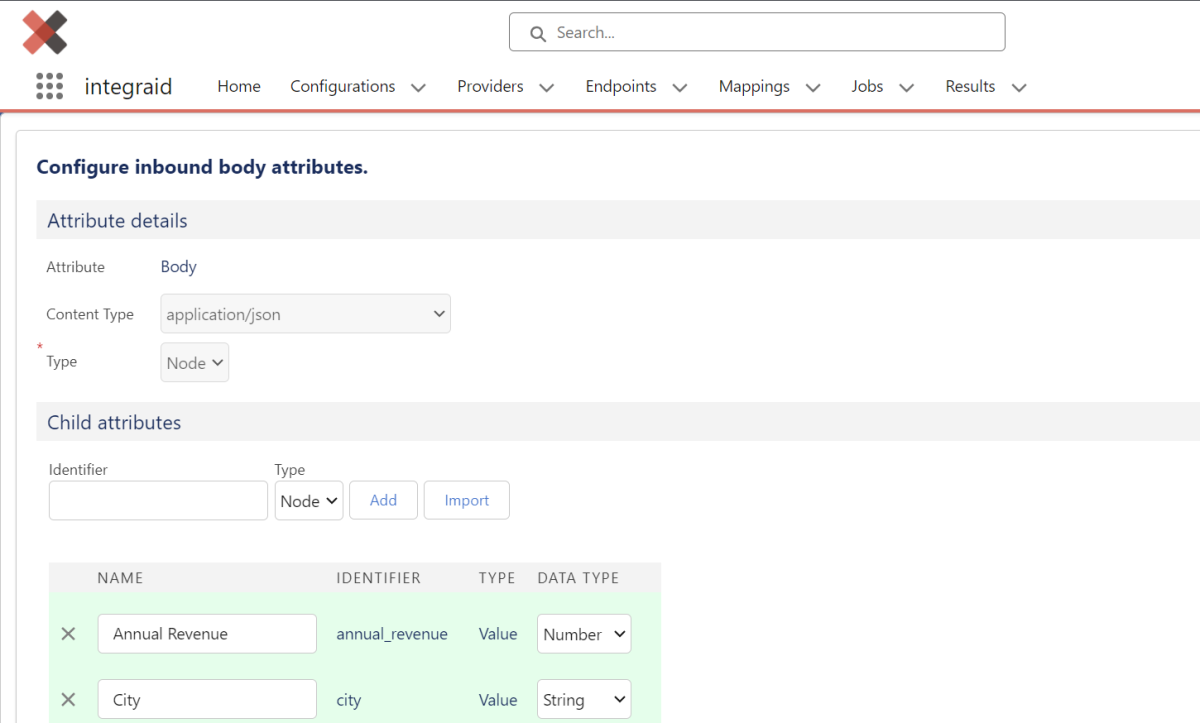 X
X
Als letztes klicken wir auf den Button “Save”, die Attribute werden gespeichert und der Endpunkt ist fertig konfiguriert.
- Mapping konfigurieren: Der vierte Schritt ist die Konfiguration des Mappings. Wir legen ein neues Mapping an, das die Verbindung zwischen der Struktur im Endpunkt und den Salesforce-Daten herstellt. Wir benennen das Mapping und verknüpfen es mit dem Endpunkt “Company Enrichment”.
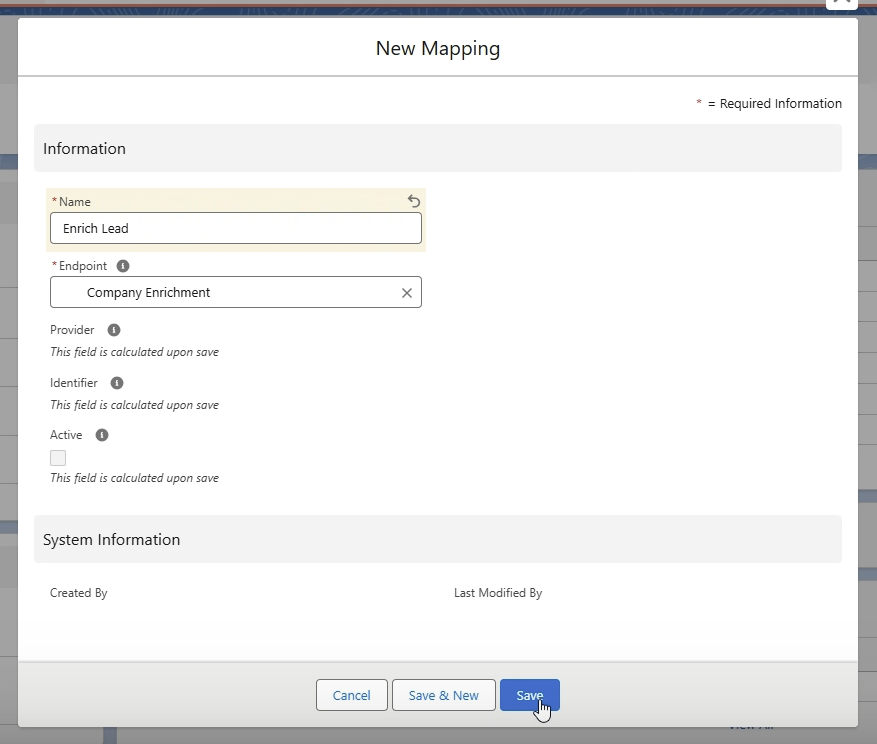 X
X
Als erstes definieren wir nun die Scope, indem wir auf “Add Scope” klicken. Hierbei wählen wir Lead als unsere Primary Scope.
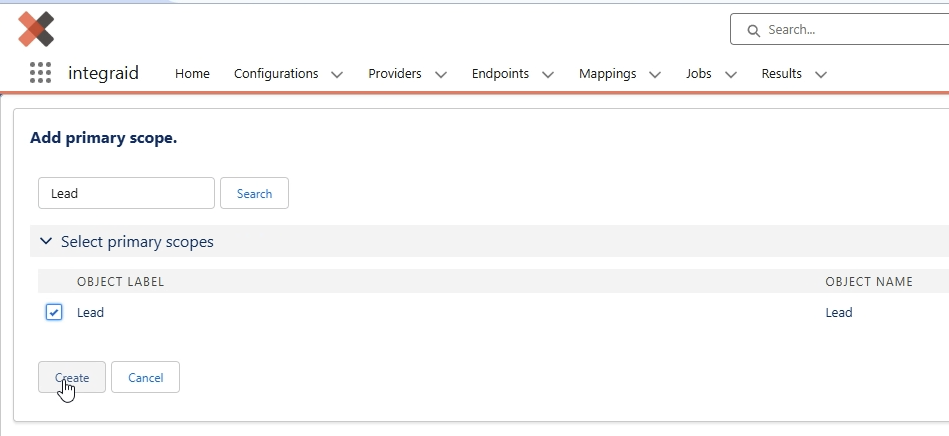 X
X
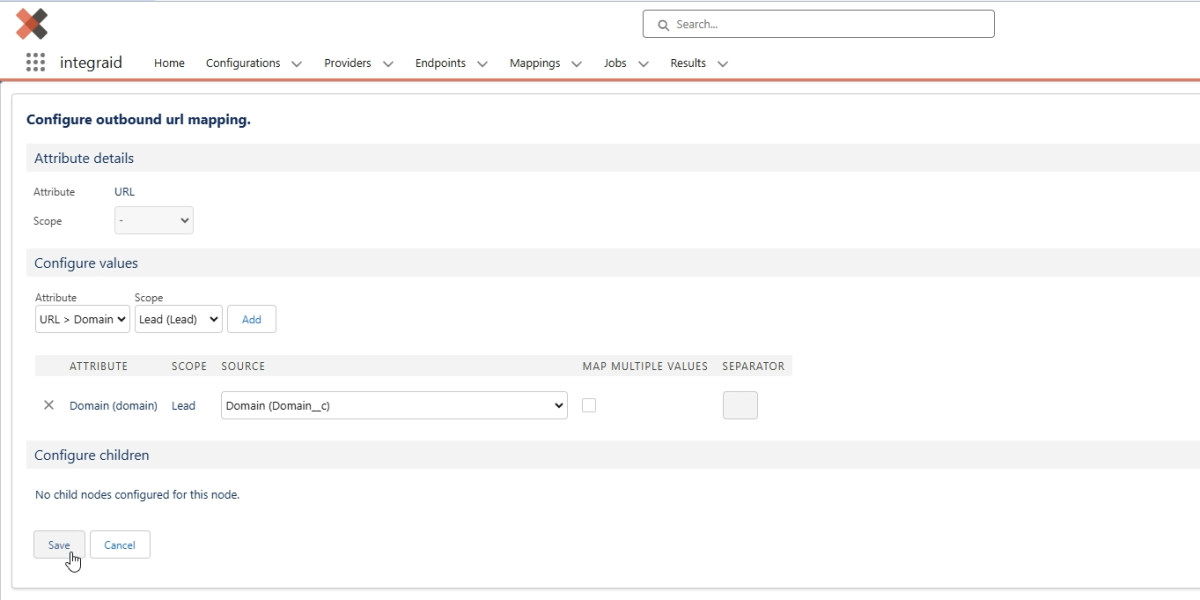
Outbound konfigurieren: Das Attribut "Domain" wird hierbei dem Formelfeld zugeordnet, das die Domain aus dem Webseitenfeld extrahiert. Dafür klicken wir auf “Add” und wählen bei Source anschließend das vorher angelegte Formelfeld “Domain__c”.
 X
X
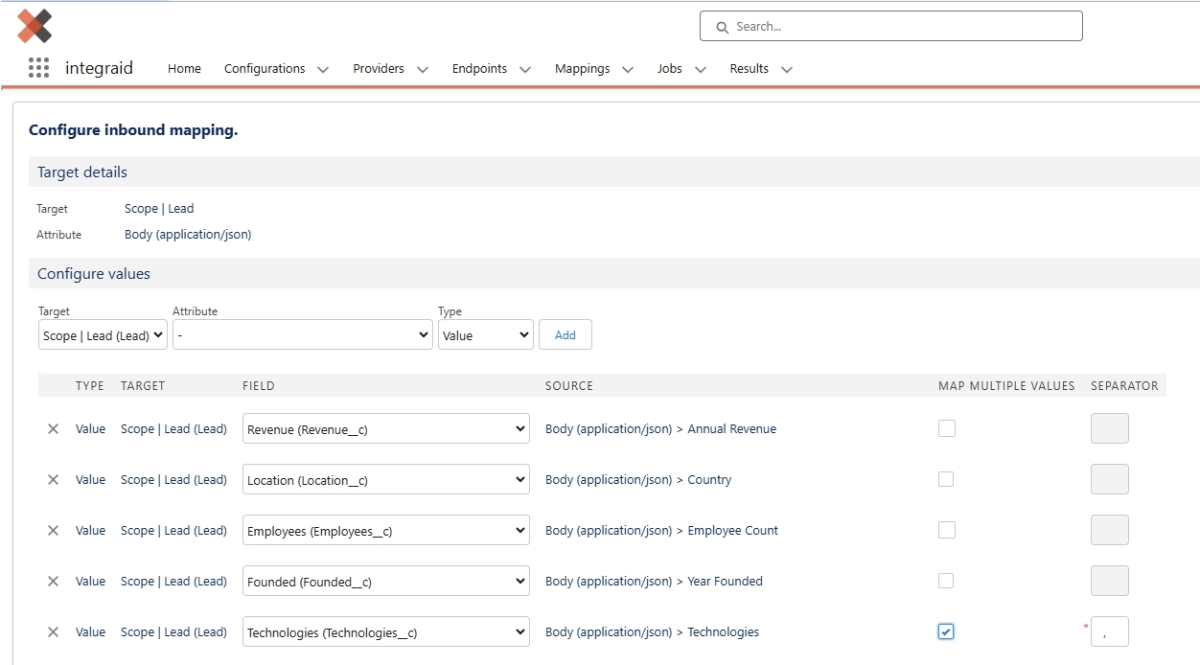
Inbound konfigurieren: Hier werden die Felder im Leadobjekt den Attributen der Abstract API-Antwort zugeordnet. Wir befüllen unsere zuvor angelegten Felder:
- "Annual Revenue" wird dem Feld "Revenue" zugeordnet.
- "Country" wird dem Feld "Location" zugeordnet.
- "Employee Count" wird dem Feld "Employees" zugeordnet.
- "Founded" wird dem Feld "Founded" zugeordnet.
- "Technologies" wird dem Feld "Technologies" zugeordnet. Dabei wird konfiguriert, dass die Werte des Arrays als kommaseparierte Liste in das Textfeld geschrieben werden, indem wir “Map Multiple Values” anhaken und bei “Seperator” ein Komma eintragen.
 X
X
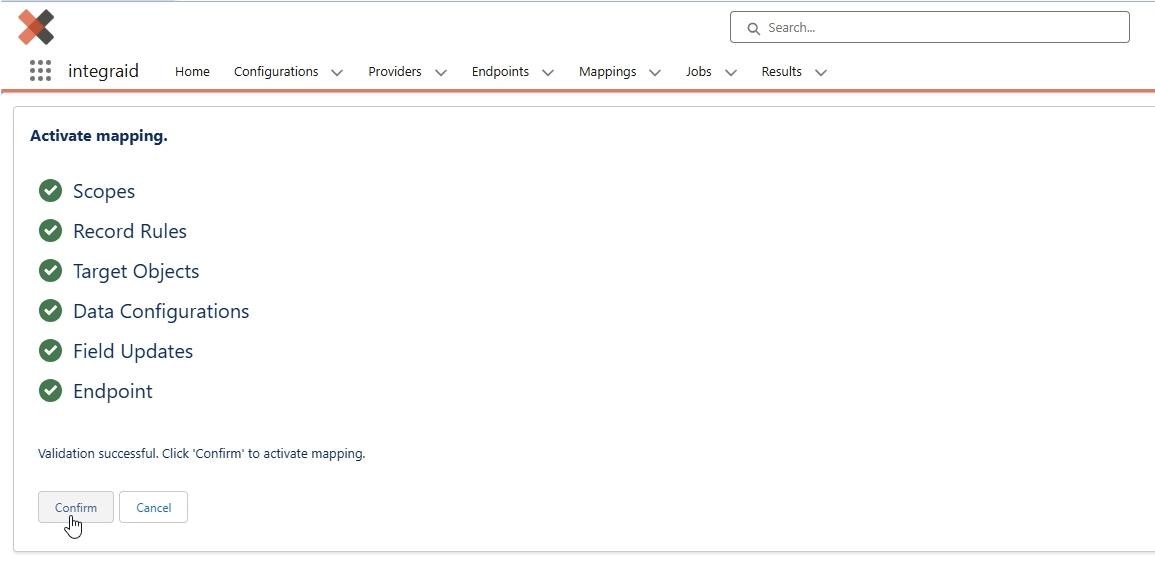
Als letztes Aktivieren wir noch das Mapping, indem wir auf den Button “Activate” klicken und schließen damit die Konfiguration in integraid ab.
 X
X
3.4.3. Konfiguration in Salesforce Flow
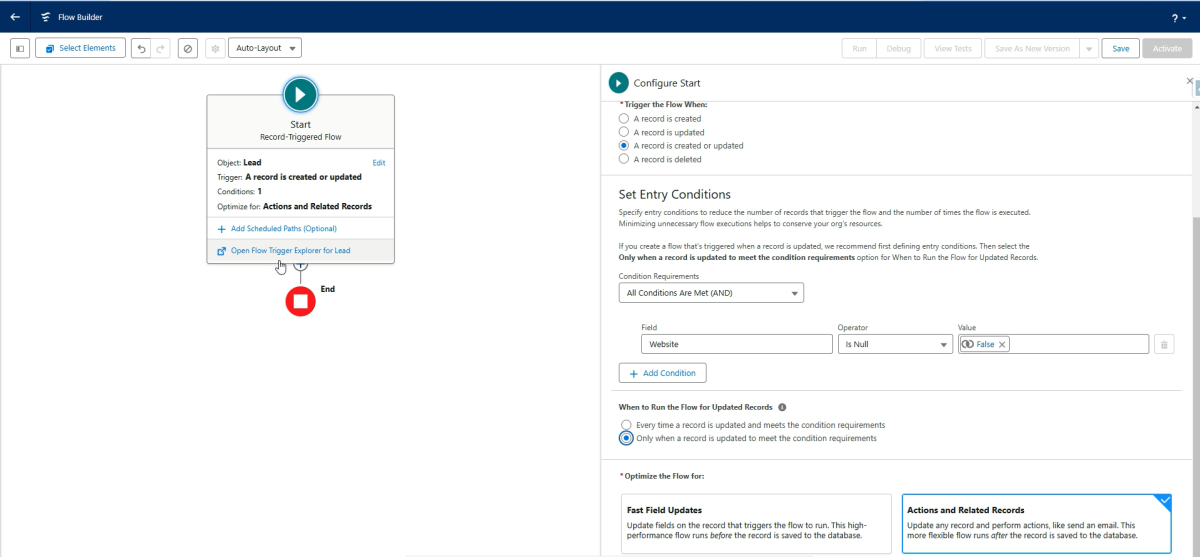
Als erstes erstellen wir einen neuen Record-Triggered Flow in unserem Salesforce System. Der Flow soll dann ausgelöst werden, wenn das Webseitenfeld im Leadobjekt erstmalig befüllt wird.
 X
X
Anschließend fügen wir einen asynchronen Pfad hinzu, da nach einer Datenänderung (Update/Insert) in Salesforce kein direkter Callout erlaubt ist.
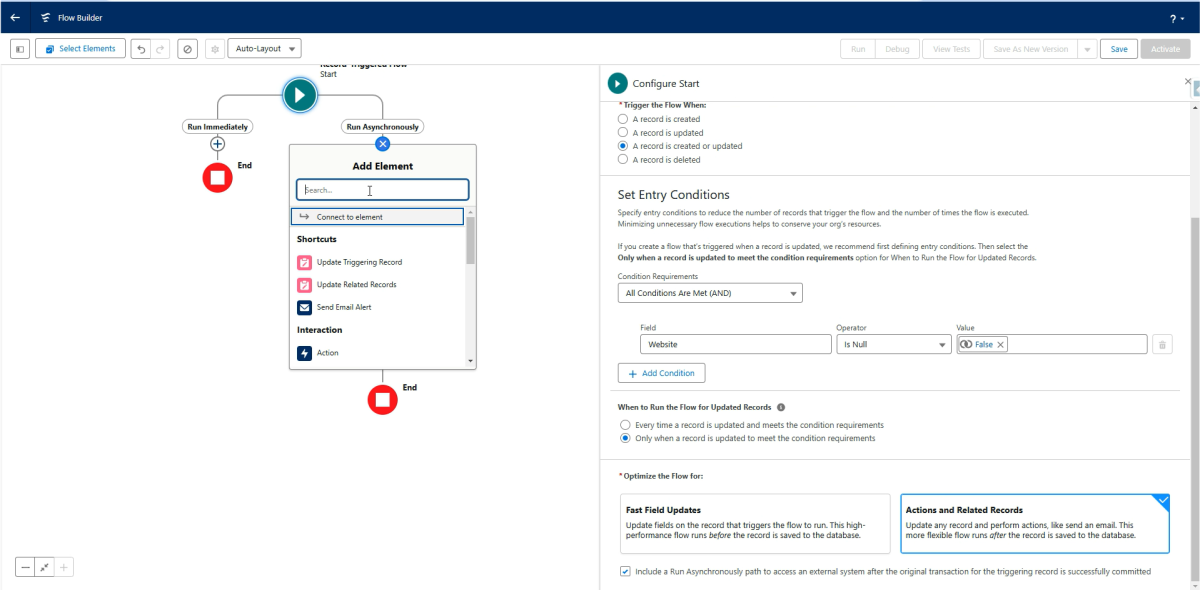 X
X
Nun müssen wir eine Variable erstellen, indem wir die Toolbox* oben links im Flow Builder öffnen und auf “New Resource” klicken. Hier erstellen wir folgende Variable:
- Resource Type: Variable
- API Name: Ids
- Data Type: Text
- Allow multiple values: checked
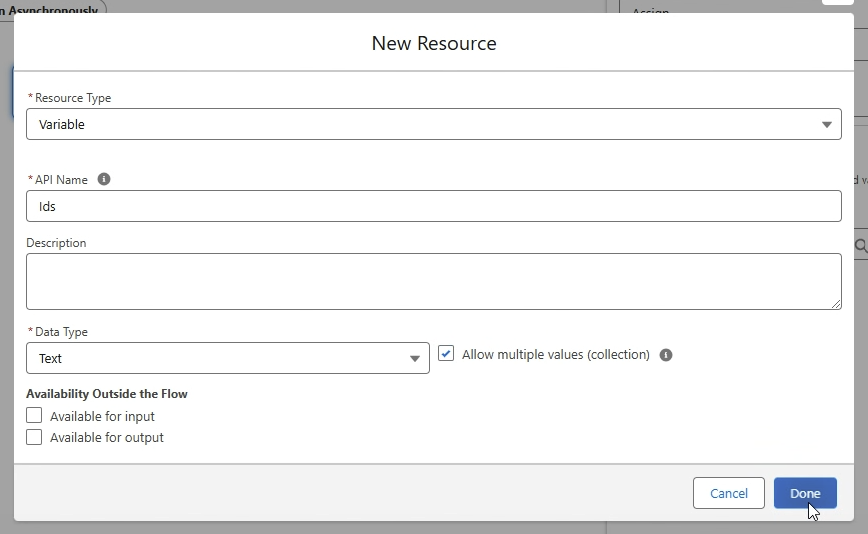 X
X
Als nächstes fügen wir ein Assignment- Element hinzu, in dem die Ressource namens "IDs" mit der ID des Leads befüllt wird, der die Logik auslöst.
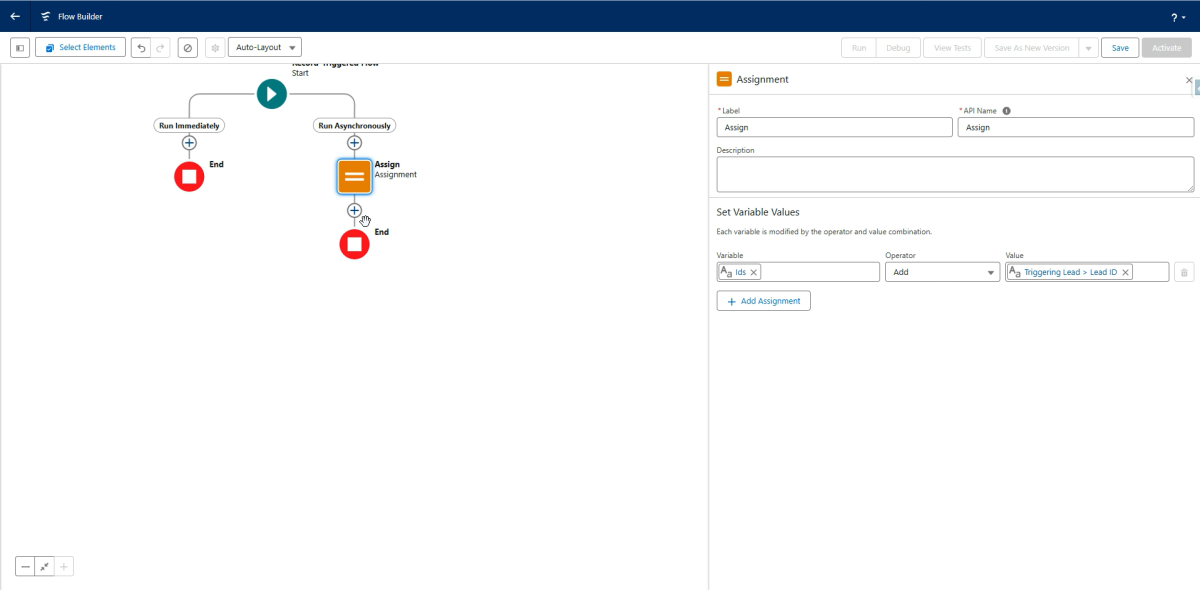 X
X
Jetzt fügen wir einen integraid Callout hinzu. Die zuvor erstellte Mapping-ID wird als Parameter übergeben, und die "IDs"-Variable wird als Parent-ID übergeben.
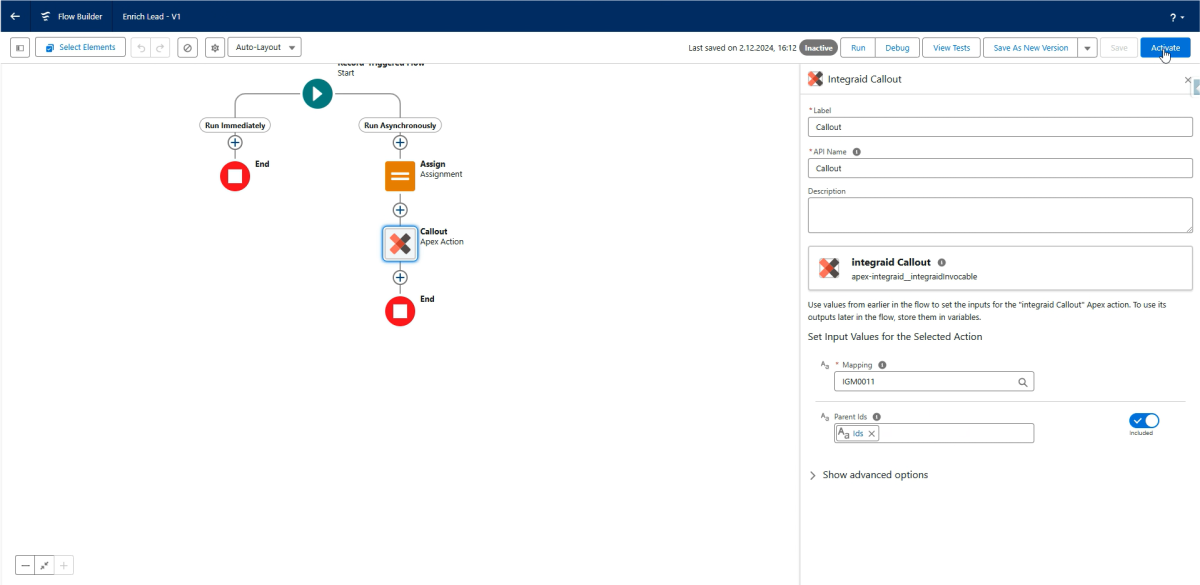 X
X
Abschließend speichern und aktivieren wir den Flow und schließen somit die Konfiguration ab.
3.4.4. Ergebnis
Wir tragen eine Website in das Feld “Website” auf Lead-Ebene ein und laden die Seite neu. Wir sehen, dass alle Felder korrekt befüllt wurden.
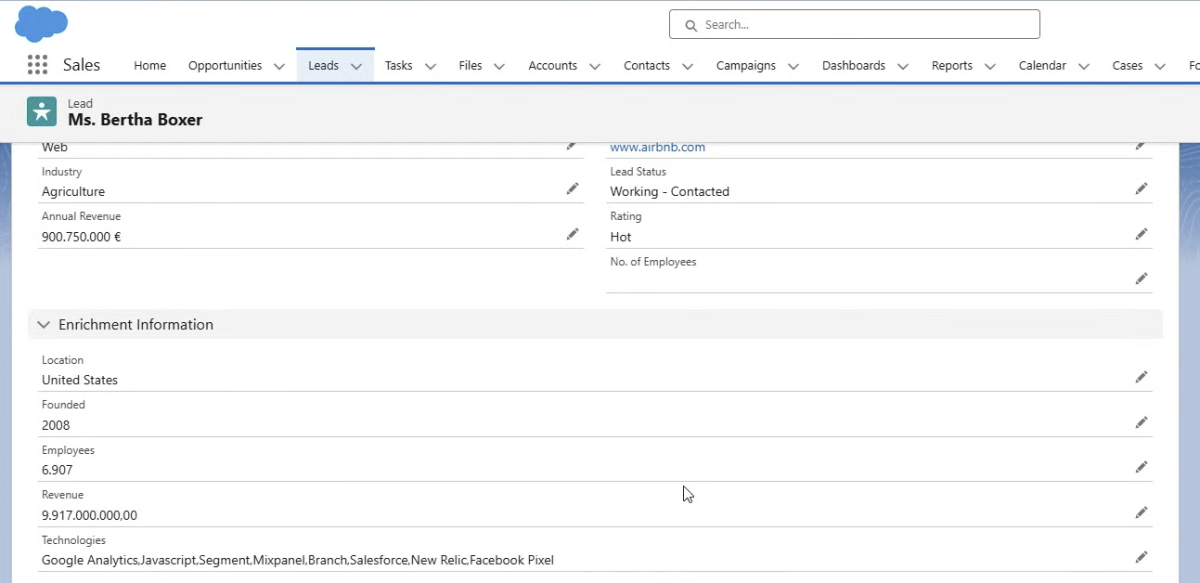 X
X
Ablauf im Detail:
1. Webseite eingeben: Ein Benutzer gibt eine Webseite in das Webseitenfeld eines Leads in Salesforce ein und speichert den Datensatz.
2. Flow wird ausgelöst: Der konfigurierte Flow wird durch die Speicherung des Leads ausgelöst.
3. Callout an Abstract API: Der Flow führt einen Callout über integraid an Abstract API aus.
4. Daten werden abgerufen: Abstract API liefert Daten zur eingegebenen Webseite zurück.
5. Felder werden befüllt: Die zurückgelieferten Daten werden in die entsprechenden Felder des Leadobjekts in Salesforce geschrieben.
6. Lead wird neu geladen: Wenn der Lead neu geladen wird, sind die Felder mit den von Abstract API abgerufenen Daten befüllt.
Diese Schritte ermöglichen es, die Informationen von Abstract API direkt in Salesforce zu integrieren und den Lead-Datensatz anzureichern.
4. Fehlerbehandlung
Je vielfältiger die Funktionalität eines Systems, desto komplexer die Konfiguration. Dabei passieren Fehler. Ein zentraler Fokus von integraid ist es, Nutzer bei der Analyse von auftretenden Konfigurationsfehlern bestmöglich zu unterstützen und Eingabefehler direkt zu vermeiden.
4.1. Fehler bei Dateneingabe
Bei Fehlern durch Fehleingaben oder Verbindungsproblemen erhält der Nutzer einen entsprechenden Hinweis.
Wird kein Hinweis auf einen Fehler ausgegeben, kann grundsätzlich davon ausgegangen werden, dass die ausgelöste Aktion erfolgreich war.
Angezeigte Fehlermeldungen entstammen dabei teilweise angeschlossenen Drittsystemen, der Applikation integraid oder Salesforce selbst.
Sollte eine Fehlermeldung unklar sein, empfehlen wir den für die Installation verantwortlichen Salesforce-Administrator zu Rate zu ziehen. Sollte auch dieser nicht helfen können, wende dich einfach per Email an support@integraid.com und sende uns einen Screenshot der Fehlermeldung, damit wir dir direkt helfen können.
4.2. Fehler bei im Hintergrund ausgeführten Aktionen
Zur besseren Übersicht wird ein Großteil der im Hintergrund durchgeführten Aktionen in einem dafür eingerichteten Objekt „Result“ gespeichert. Dies ermöglicht die Nachvollziehbarkeit von im Hintergrund oder automatisiert durchgeführten Aktionen.
Eine Liste dieser Ergebnisdatensätze sind im Reiter „Results“ zu finden. Im Erfolgsfall wird die Nachricht „Success“ angezeigt. Im Fehlerfall der entsprechende Fehler.
Sollten bei mehreren, gleichzeitig ausgeführten Callouts jeweils derselbe Fehler auftreten, werden die Fehlermeldung in eine Mail zusammenfasst, welche der Admin (oder der unter "Error Email Configuration" definierte Benutzer) erhält. Zudem gibt es ein 15-minütiges Zeitfenster, in welchem nach einer Fehler-Mail keine weiteren Mails mit Fehlermeldungen desselben Fehlers mehr gesendet werden. Sollte ein Fehler weiterhin auftreten, wird daher nur alle 15 Minuten eine Fehler-Mail geschickt.
Hinweis zur Freigabe von Speicherplatz: Zur Freigabe von Speicherplatz, der über die Zeit durch angesammelte "Result"-Datensätze verbraucht wurde, kann die Schaltfläche "Clear" in beliebiger Listenansicht des "Results"-Reiters verwendet werden. Bitte beachte, dass bei Nutzung dieser Schaltfläche immer sämtliche "Result"-Datensätze ungeachtet der aktuell dargestellten Listenansicht gelöscht werden!
5. Glossar
Objekte
Objekte sind Datensatztypen innerhalb der Salesforce Datenbank. Beispiele von Standardobjekten, die in Salesforce bereits angelegt sind, sind Accounts, Kontakte und Opportunities. Neben den in Salesforce standardmäßig existierenden Objekten können beliebige Custom-Objekte in Salesforce zukonfiguriert werden.
Merge-Felder
Merge-Felder ermöglichen es, auf Felder des aktuellen oder verwandter Datensätze in Salesforce zuzugreifen. Sie werden verwendet, um kontextbezogene Informationen zu holen, die für die Integration benötigt werden.
Merge-Attribute
Merge-Attribute ermöglichen den Zugriff auf die Werte der eingehenden oder ausgehenden Daten, die von oder zu der externen Schnittstelle gesendet werden. Sie ermöglichen es, Werte aus der Response oder dem Request zu extrahieren, um sie in Salesforce zu verwenden oder zu transformieren.
Invocable
Eine Invocable in integraid ist eine wiederverwendbare Logik, die über andere Systeme, wie z.B. Flows, aufgerufen werden kann. Eine Invocable kann ein Mapping ausführen und so die Kommunikation mit einer externen Schnittstelle anstoßen.
Array
Ein Array ist eine geordnete Liste von Elementen. In der Programmierung und in Datenformaten wie JSON wird ein Array verwendet, um mehrere Werte unter einem einzigen Namen zu speichern. Arrays können einfache Datentypen wie Zahlen oder Strings enthalten, aber auch komplexere Objekte oder andere Arrays. Bei der Integration mit externen Schnittstellen können Arrays in den Anfragen oder Antworten vorkommen. In integraid kann ein Array als eine Menge von Werten behandelt werden, die entweder aus Salesforce an eine Schnittstelle gesendet oder von der Schnittstelle empfangen und in Salesforce gespeichert werden.
JSON (JavaScript Object Notation)
JSON ist ein leichtgewichtiges Datenformat, das häufig für die Übertragung von Daten zwischen einem Server und einer Webanwendung verwendet wird. Es basiert auf einer einfachen Textstruktur, die aus Schlüssel-Wert-Paaren besteht. JSON kann einfache Datentypen wie Strings, Zahlen, Boolesche Werte und Arrays enthalten, aber auch komplexere Objekte.